6 Octobre 2016
Analyse des performances du programme Spark
Sauvegarde de l’historique d’exécution d’une application
Programme Scala
Il est possible d’analyser le temps d’exécution d’un programme Spark avec son interface web :
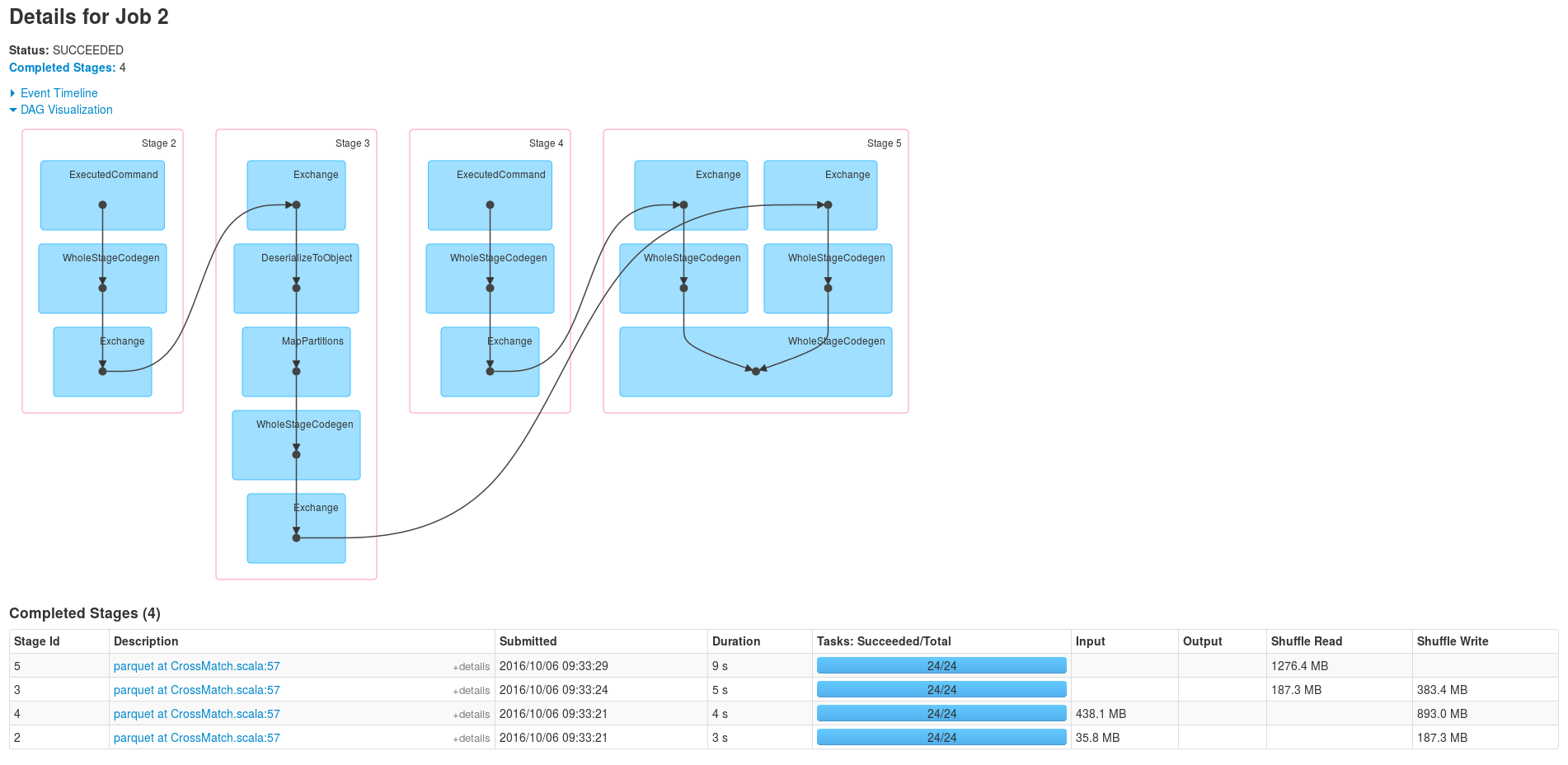
Schéma d’exécution du Crossmatch (sans la lecture des fichiers parquets)
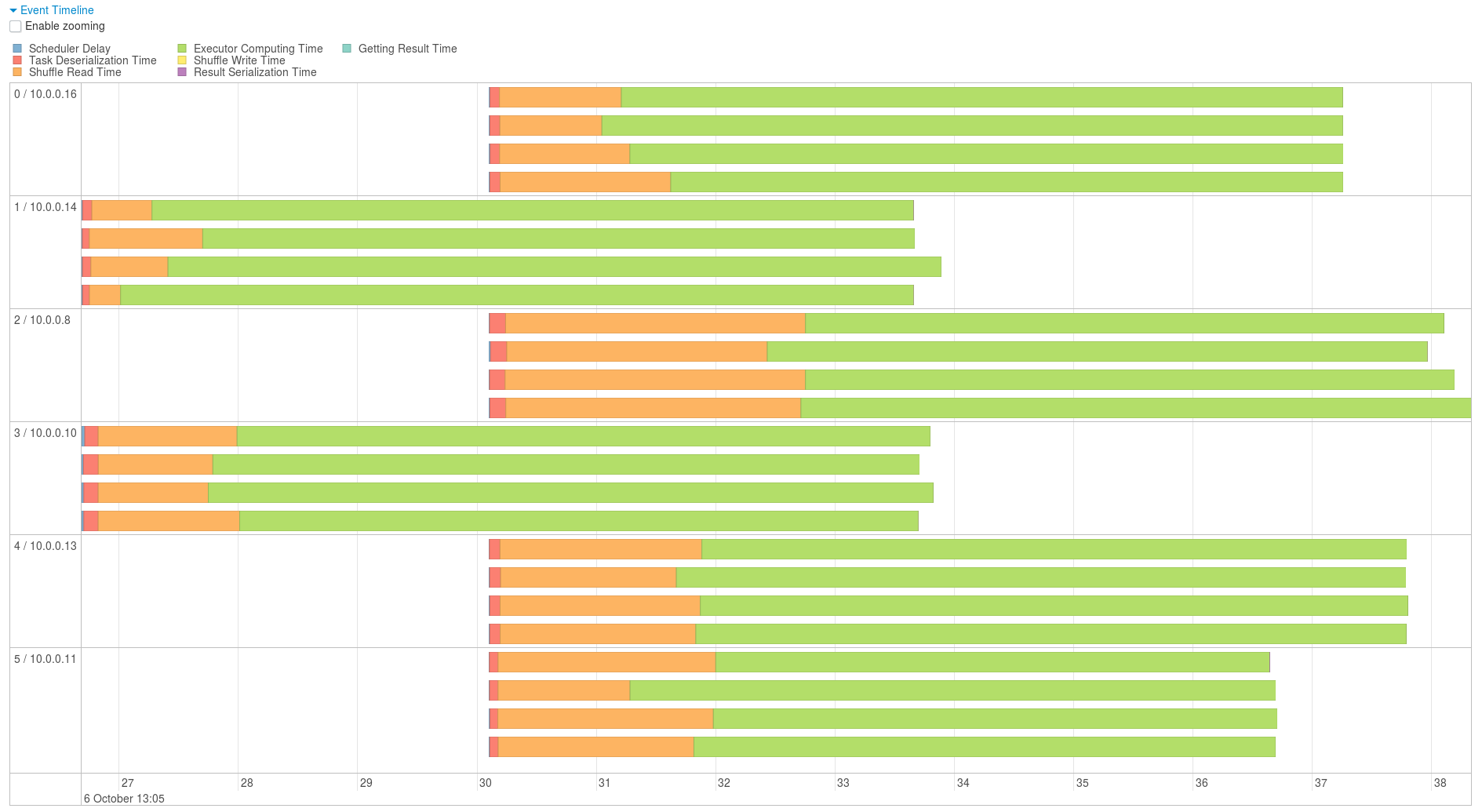
La dernière étape correspond au join, voyons ce qu’il s’y passe de plus près :
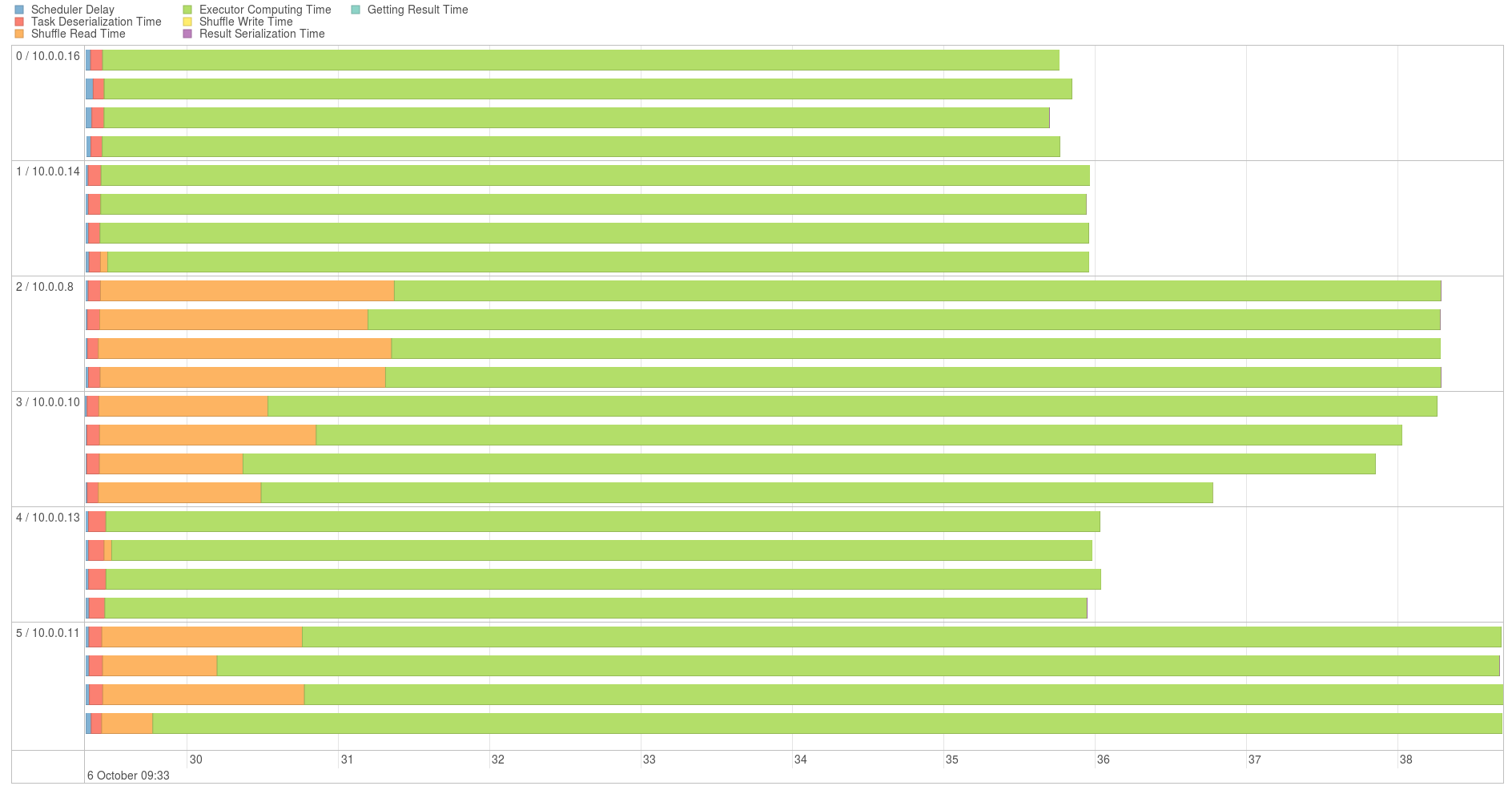
Graphique d’exécution du join
On peut observer que les partitions (chaque ligne en est une) sont uniformément réparties. Aussi le shuffling ne correspond qu’à une faible partie du temps (environ 2 sec sur les 10)
Programme Java
Comparons maintenant avec l’exécution du programme écrit en Java et stockant les catalogues sous forme de RDD
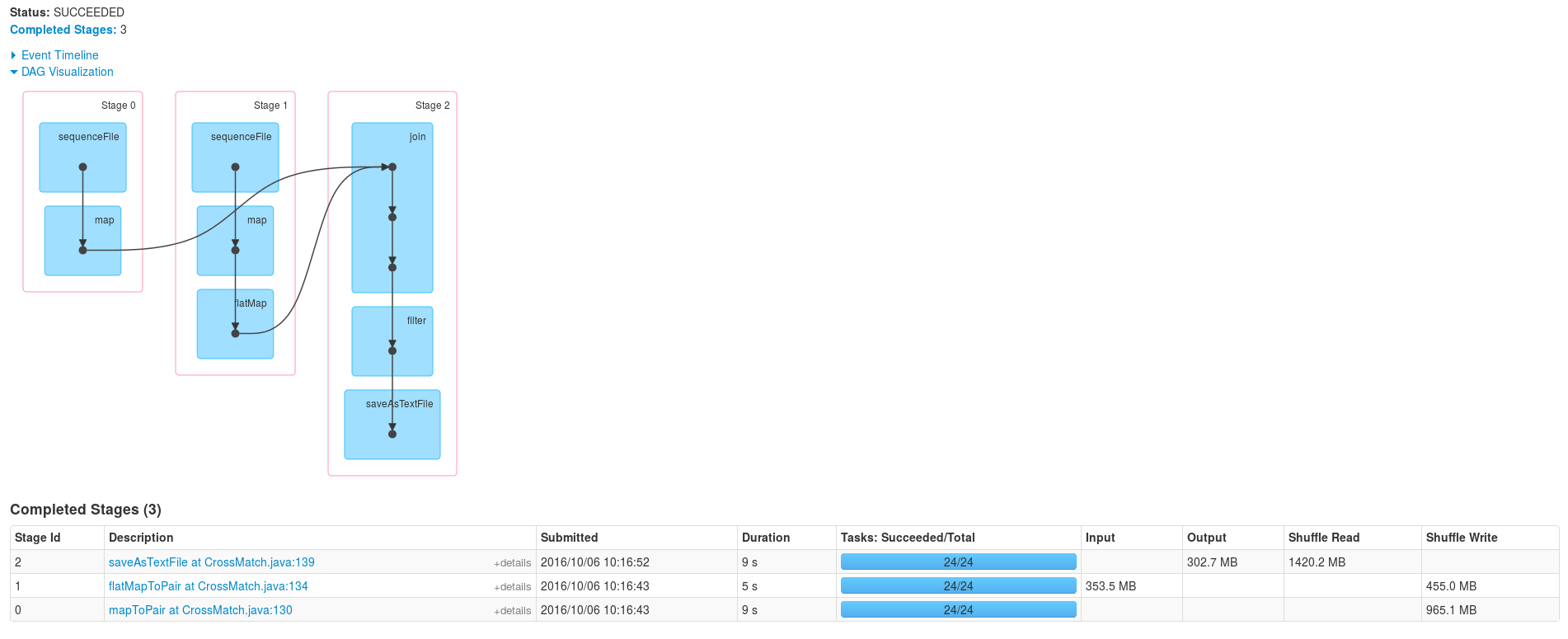
Execution
L’exécution de ce programme semble plus simple, voyons maintenant le join :
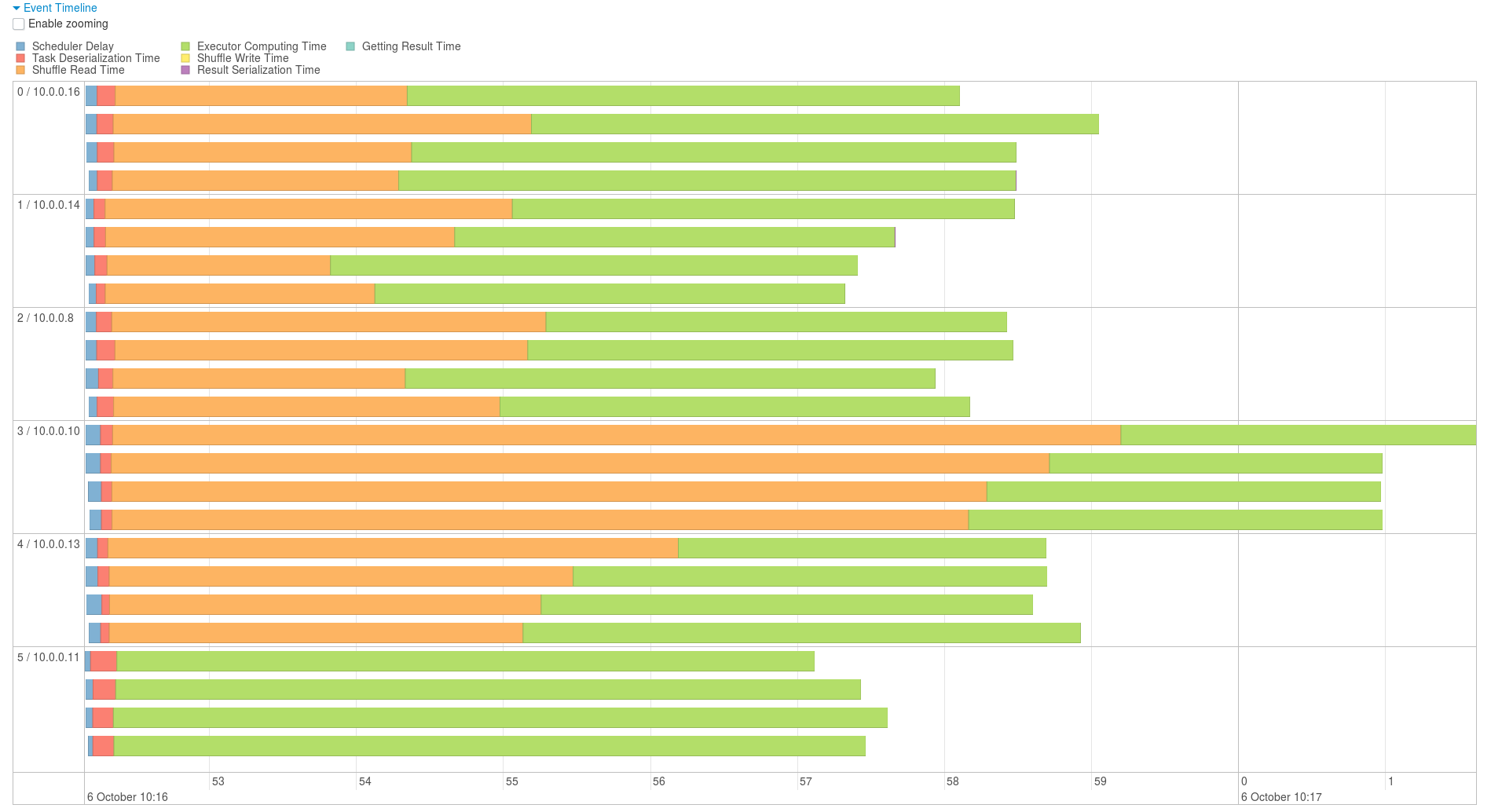
Graphique join Java
Au vu de ces résultat il semble que l’optimisation du programme Scala devrais surtout se faire au niveau du calcul qui met 3 a 4 secondes de plus que le programme en Java ainsi que les différents traitement pre join qui ralentissent l’execution.
Analyse de l’effet de la méthode répartition au moment de la lecture des fichiers parquets
Illustration