22 Septembre 2016
Mise en place d’un cluster Jenkins
Pour l’exemple je vais mettre en place des machines esclaves capable de compiler des images docker. Il est tout à fait possible de modifier les images utilisées afin de pouvoir compiler n’importe quel language en installant les dépendances necessaires dans l’image.
1. Création des images esclaves
FROM openjdk:alpine
MAINTAINER Paul TREHIOU <paul.trehiou@gmail.com>
RUN apk -U add docker curl
RUN curl --create-dirs -sSLo /usr/share/jenkins/swarm-client-2.2-jar-with-dependencies.jar https://repo.jenkins-ci.org/releases/org/jenkins-ci/plugins/swarm-client/2.2/swarm-client-2.2-jar-with-dependencies.jar
ENTRYPOINT ["java", "-jar", "/usr/share/jenkins/swarm-client-2.2-jar-with-dependencies.jar"]2. Installation du plugin sur le container maitre
Le plugin est le suivant
3. Démarage des machines esclaves
docker service create --mode global --mount type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock localhost:5000/jenkins-slave -master http://cds-stage-ms4:8888/ -username $USERNAME -password $PASSWORDDans l’idéal créer un compte utilisateur spécial
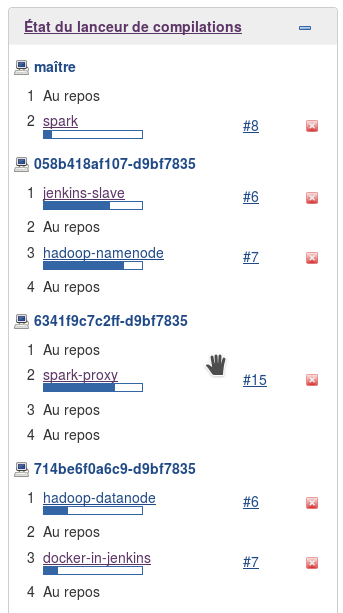
Capture d’écran compilation simultanée
Container Jenkins maitre en HA
Pour le moment le container maitre est lié à une machine, il serait intéressant de pouvoir l’utiliser indépendament depuis chaque machine.
Une solution est d’utiliser glusterfs pour avoir accès au volume Jenkins indépendament de la machine.
Schéma

Schéma de fonctionnement GlusterFS
Création du volume partagé
gluster volume create docker stripe 3 replica 2 cds-stage-ms1:/data/glusterfs cds-stage-ms2:/data/glusterfs cds-stage-ms3:/data/glusterfs cds-stage-ms4:/data/glusterfs cds-stage-mv1:/data/glusterfs cds-stage-mv2:/data/glusterfsLe paramètre replica indique le nombre de copie de chaque fichier, stripe indique
Problème éventuel lors de la création
volume create: docker: failed: /data/glusterfs is already part of a volumeCela peut arriver si le dossier utilisé (appelé brick) à été utilisé précédemment dans un autre volume (même si ce volume n’existe plus)
La solution est de supprimer le dossier et d’en créer un nouveau.
Il se trouve que Gluster ajoute un attribut au dossier qui l’empeche d’être utilisé dans deux volumes
Démarage du volume
gluster volume start dockerMontage du volume sur tous les noeuds
Il existe normalement un plugin Docker permettant de simplifier cette tache mais qui ne fonctionne pas en mode swarm. On va donc monter ce volume à un endroit identique sur chaque noeud et y créer un dossier jenkins qui contiendra les données.
mkdir /mnt/gluster-docker
echo "localhost:/docker /mnt/gluster-docker glusterfs defaults,_netdev 0 0" >> /etc/fstabExemple :
trehiou@cds-stage-ms4 /m/gluster-docker> dsh -aMc 'ls -lha /mnt/gluster-docker'
cds-stage-ms1: total 20K
cds-stage-ms1: drwxrwxr-x 6 1010 1010 4,0K sept. 22 12:15 .
cds-stage-ms1: drwxr-xr-x 3 root root 4,0K sept. 22 12:16 ..
cds-stage-ms1: drwxr-xr-x 2 root root 4,0K sept. 22 12:15 jenkins
cds-stage-ms1: drwxr-xr-x 2 1015 1014 4,0K sept. 22 12:15 test
cds-stage-ms1: drwxr-xr-x 3 root root 4,0K sept. 22 12:09 .trashcan
cds-stage-mv1: total 20K
cds-stage-mv1: drwxrwxr-x 6 1010 1010 4,0K sept. 22 12:15 .
cds-stage-mv1: drwxr-xr-x 3 root root 4,0K sept. 22 12:16 ..
cds-stage-mv1: drwxr-xr-x 2 root root 4,0K sept. 22 12:15 jenkins
cds-stage-mv1: drwxr-xr-x 2 1015 1014 4,0K sept. 22 12:15 test
cds-stage-mv1: drwxr-xr-x 3 root root 4,0K sept. 22 12:09 .trashcan
cds-stage-ms2: total 20K
...
localhost:/docker 2,3T 519G 1,7T 24% /mnt/gluster-dockerAgrandissement du volume
Il est possible de rajouter des noeuds glusterfs à un volume existant
Arrêt du container Jenkins et migration des données
trehiou@cds-stage-ms4 /m/gluster-docker> docker stop jenkins
jenkins
trehiou@cds-stage-ms4 /m/gluster-docker> docker rm jenkins
jenkins
trehiou@cds-stage-ms4 /m/gluster-docker> docker volume inspect jenkins
[
{
"Name": "jenkins",
"Driver": "local",
"Mountpoint": "/data/docker/volumes/jenkins/_data",
"Labels": {},
"Scope": "local"
}
]
trehiou@cds-stage-ms4 /m/gluster-docker> sudo -i
root@cds-stage-ms4 ~# mv /data/docker/volumes/jenkins/_data/* /mnt/gluster-docker/jenkins/Démarage du service et montage sur le dossier GlusterFS
docker service create -p 8888:8080 --mount type=bind,src=/mnt/gluster-docker/jenkins/,dst=/var/jenkins_home --mount type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock --network jenkins-net --name jenkins localhost:5000/docker-in-jenkinsCe service Jenkins est maintenant plus fiable car si jamais la machine faisant tourner le container venais à avoir un problème, n’importe quelle autre machine dispose de la configuration de Jenkins et peut prendre le relais immédiatement.
Mise a jour du service slave :
docker service rm jenkins-slave
docker service create --name jenkins-slave --mode global --network jenkins-net --mount type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock localhost:5000/jenkins-slave -master http://jenkins:8080/ -username nyanloutre -password yagi20Démonstration
Forçons le container à s’arrèter sur la machine ou se trouve le service Jenkins :
trehiou@cds-stage-ms1:~$ docker stop jenkins.1.f0qfg0hszromazs2lcx571zao
trehiou@cds-stage-ms4 /m/gluster-docker> docker service ps jenkins
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
bmsdst0aurv4a0fe5a555j2kd jenkins.1 localhost:5000/docker-in-jenkins cds-stage-ms1 Running Running 20 seconds ago
f0qfg0hszromazs2lcx571zao \_ jenkins.1 localhost:5000/docker-in-jenkins cds-stage-ms1 Shutdown Failed 26 seconds ago "task: non-zero exit (143)"On voit que immédiatement un autre noeud à pris le relai, allons voir la page web : Après une dizaine de secondes sans réponse (le temps que le nouveau container Jenkins démare) 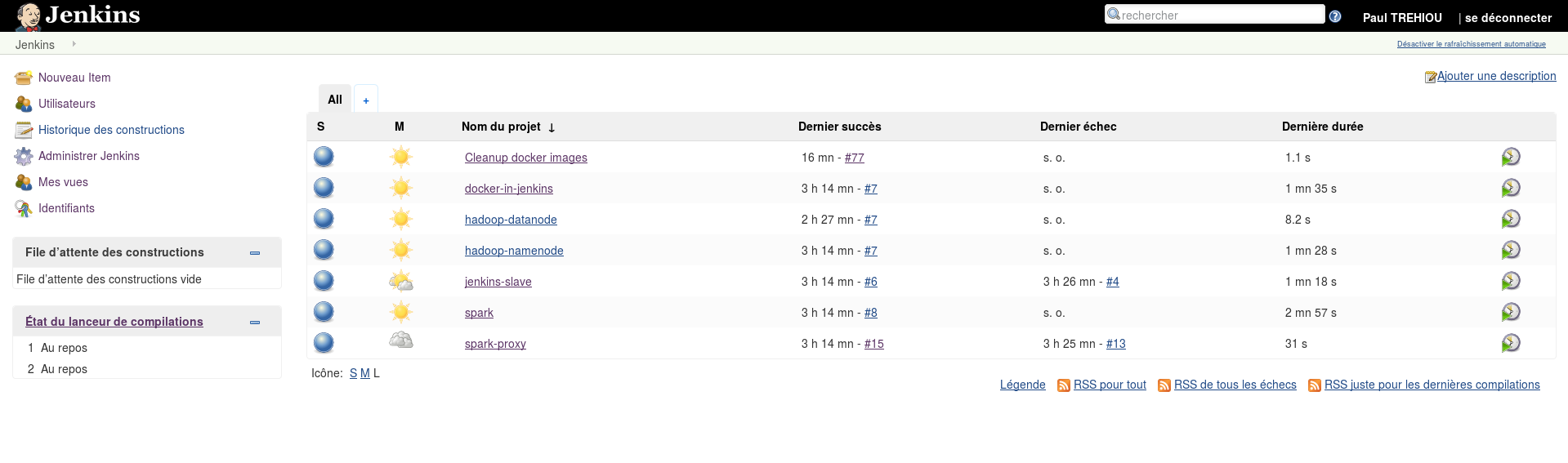
On peut à présent étendre cette fonction à d’autre points critiques comme le namenode hdfs ainsi si soit service venait à être relocalisé il ne perdrais pas ses fichiers, il faudra juste voir si les datanodes ne font pas de timeout durant le redémarage du service (qui garde en plus le même nom de domaine à savoir hdfs://hdfs-namenode:8020 ou sinon comment augmenter la durée du timeout
C’est par contre beaucoup moins utile sur le master node spark qui est complètement stateless, c’est à dire qu’il est peu important de sauvegarder sont état car il ne stocke rien.
Container HDFS namenode en HA
Le dossier à sauvegarder est /hadoop
docker service create --name hdfs-namenode -e CORE_CONF_fs_defaultFS=hdfs://hdfs-namenode:8020 -e CLUSTER_NAME=test -e CORE_CONF_hadoop_http_staticuser_user=root -e HDFS_CONF_dfs_webhdfs_enabled=true -e HDFS_CONF_dfs_permissions_enabled=false --network spark-net --mount type=bind,src=/mnt/gluster-docker/hdfs-namenode/,dst=/hadoop localhost:5000/hadoop-namenodeTest de fiabilité
docker kill hdfs-namenode.1.8uf1wu8f484szgouqivr88nt9Le test n’est pas concluant le namenode se réinitialise
Pistes
- Interface pour envoyer des commandes SQL à Spark
- Sécurité de Docker (comment confiner des applications fournies par des tiers, la sécurité de base de Docker suffit-elle où faut-il le configurer différement)
- Apprendre le Scala dans l’optique de simplifier le code Java actuel
- Améliorer la localisation des données sur le système de fichier partagé afin de limiter les transferts réseau
- Utiliser le code Java actuel de Francois-Xavier et le faire fonctionner en cluster pour se passer de Spark (il serait alors possible de revoir le stockage des données pour supprimer les transferts réseaux)
- Limitation des performances d’un service afin de pouvoir rendre les performances plus homogènes sur des machines hétérogènes.