Stage de Thierry Lacoste - IUT Reims - [04/04/16 au 10/06/16]
Important : cette page est réservée au suivi du stage, merci de ne pas la modifier Informations générales pour les stagiaires Pour toute information concernant ce stage : contacter AnaisSujet
Documents de travail
- ...
Stage (avril - juin 2016)
Avril
- *04
-
Le CDS fonctionne avec différents groupes de travail (astronomes, informaticiens, documentalistes). Le concept de leur travail ainsi que les différents systèmes déjà mis en place nous ont été expliqués durant cette journée par 8 présentations en amphithéâtre.
Une fois terminé, nous avons visité les lieux ainsi que les espaces mis à dispositions par le CDS (cafeteria, abris à vélo).
- *05
- Entretien avec mon maître de stage, Anaïs Oberto, afin de prendre connaissance du déroulement du stage et du travail à réaliser.
Durant cette journée j’ai eu le temps de comprendre le fonctionnement actuel de l’affichage des logs qui consiste à créer un fichier CSV chaque jour à partir de la base de données MongoDB, ceci permettant de le lire par la suite via une page HTML.
L’objectif du projet est donc de retirer la création journalière du fichier CSV pour que, lorsqu’un utilisateur accède à une page HTML, celle-ci prenne directement les informations dans la base de données grâce à un script en Python.
Pour ce deuxième jour, j’ai tout d’abord installé mon espace de travail sur une machine mise à disposition. J’ai rencontré quelques difficultés à m’adapter à celle-ci qui tourne sous Ubuntu.
Puis mon maître de stage m’a proposé plusieurs frameworks/langages, afin de parvenir aux objectifs. Il m’a fallu comprendre le fonctionnement et l’utilité de chacun d’entre eux :
-
Highcharts : framework permettant d’afficher des schémas de statistiques grâce à des données au format json.
-
MongoDB : base de données utilisée par le CDS
-
Python : langage utilisé pour créer le fichier CSV chaque jour.
-
WebAnalyzer: logiciel permettant de générer des statistiques à partir des logs d’accès.
-
Node.js : logiciel utilisant du Javascript du côté serveur.
-
Les informaticiens souhaitent que l’application réalisée soit dans un langage qu’ils connaissent. La solution du PHP est donc oubliée. Le mieux pour eux serait d’utiliser le Python. C’est pourquoi j’ai suivi quelques tutoriels pour comprendre les bases de la programmation en Python. Lors de ces prises d’informations j’ai pu trouver une solution nommée Django qui est un logiciel permettant d’utiliser du Python à la place du PHP.
- *06
-
Durant cette journée j’ai pu poursuivre mes recherches et prises d’informations.
J’ai installé quelques logiciels et programmes :
-
Python
-
Django
-
MongoDB
-
J’ai également commencé à en apprendre davantage sur l’utilisation de Django.
- *07
-
Durant cette journée j’ai pu suivre des tutoriels et commencer à mettre en place une solution avec Django.
- *08
-
Durant cette journée j’ai continué à travailler sur la mise en place de Django. J’ai pu utiliser un autre langage de programmation qui est le Gambarit (utilisé par Django pour permettre la liaison finale entre la page web et le Python).
- *11
-
Finissions de la page web + script Django. J'ai pu effectuer des test d'intéraction avec MongoDB qui ont fonctionné. En revanche un problème n'est pas résolu. Il s'agit de pouvoir vérifier plusieurs champs ayant le même "name".
- *12
-
Durant cette journée j'ai commencé à mettre en place Node.js et à comprendre son fonctionnement. De même pour la bibliothèque socket.io
- *13
-
Durant cette journée j'ai pu continuer à utiliser Node.js, créer une page web ainsi que la vérification des champs du formulaire.
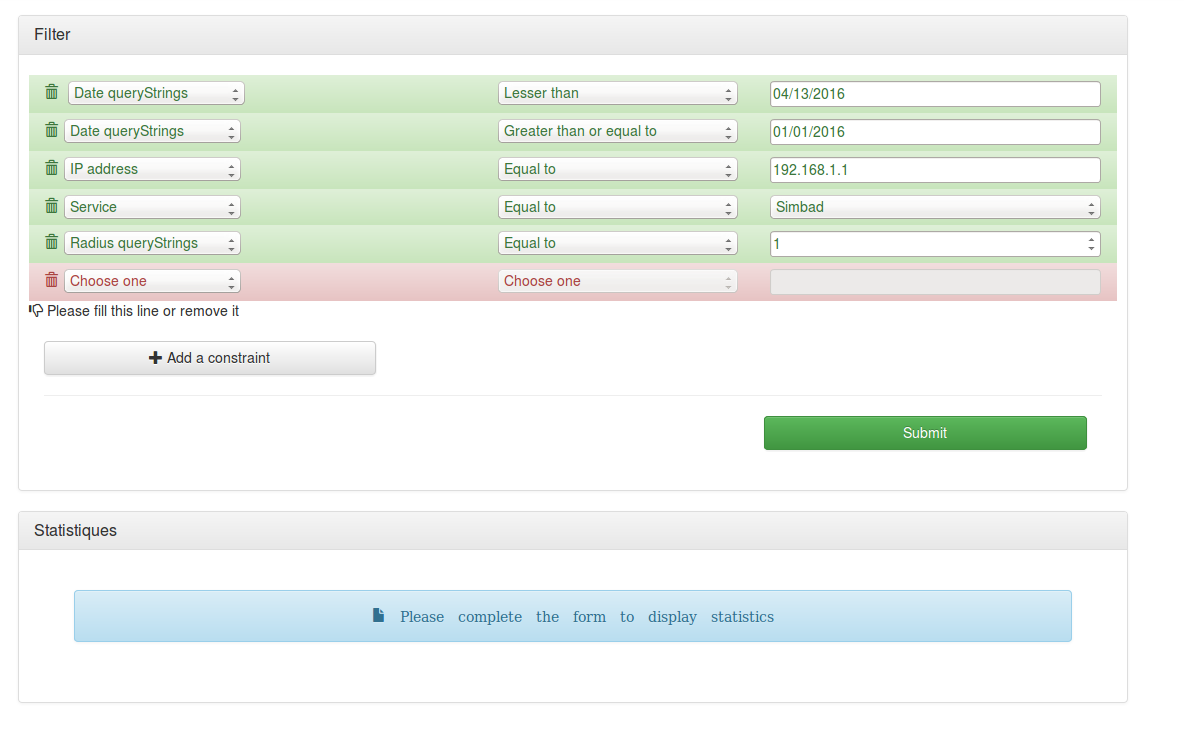
- *14
- Travail avec Socket.io et MongoDB driver sur Node.js
- *15
- Fin des tests avec Node.js ainsi que la page web
- *18
- Prise d'informations sur Logstash et travail sur sa mise en place.
- *19
- Réunion avec M. André Schaaff et Mme Anaïs Oberto pour voir les tests et travaux qui ont été réalisés et se mettre d'accord sur le travail à réaliser. Je dois donc à présent terminer la page en cours et créer deux autres pages permettant :
- De lire des fichiers csv en local ainsi que lire un fichier log mis en ligne.
- D'insérer et de supprimer des données via des scripts pythons.
- *20
- Début de réalisation du premier point.
- *21
- Travail sur le premier point.

- *22
- Travail sur le deuxième point.
- Gestion des scripts.
- Affichage des scripts et des champs permettant la saisie de leurs arguments.
- Exécution des scripts.
- Affichage du résultat sous forme de graphiques.
- *25
- Travail sur le deuxième point.
- Gestion des arguments et transmission de ceux-ci aux scripts.
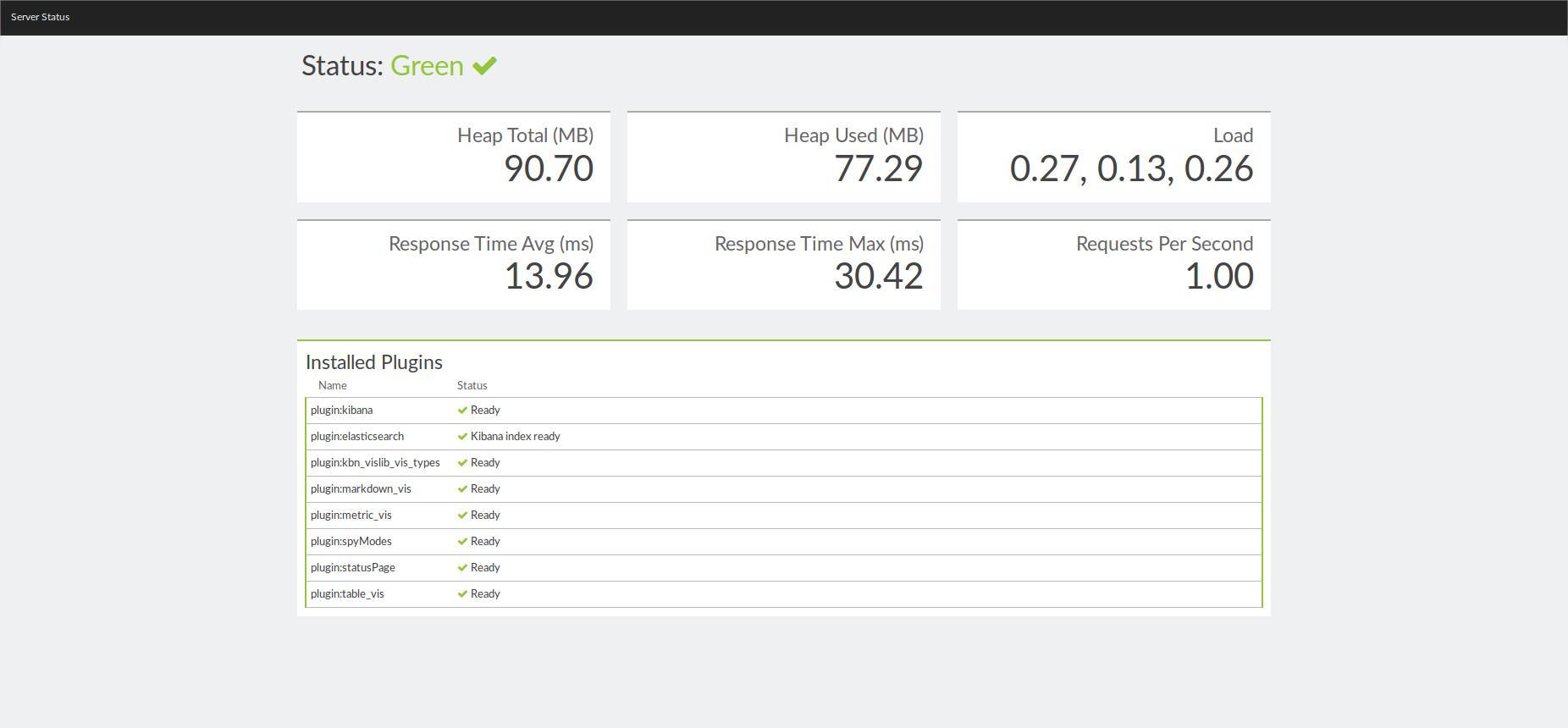 Configuration de logstash pour qu'il ait comme entrée les données de la base MongoDB (échec)
Configuration de logstash pour qu'il ait comme entrée les données de la base MongoDB (échec) - *26
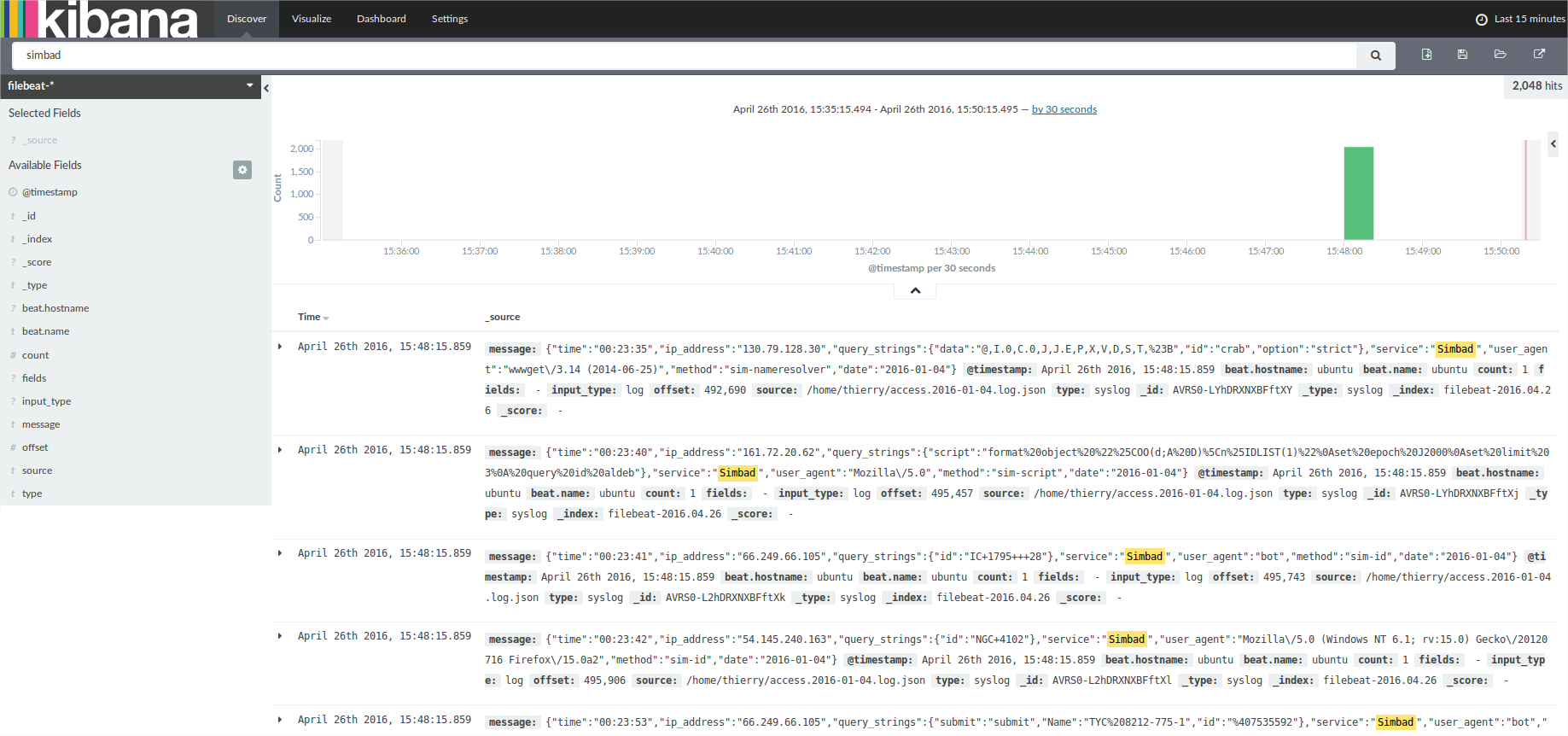
- Configuration de logstash:
- Elasticsearch arrive à lire le fichier json "access.2016-01-04.log.json" grâce à filebeat. Kibana reçoit les données et les affiche ligne par ligne mais aucun affichage sous forme graphique ne fonctionne.
- *27
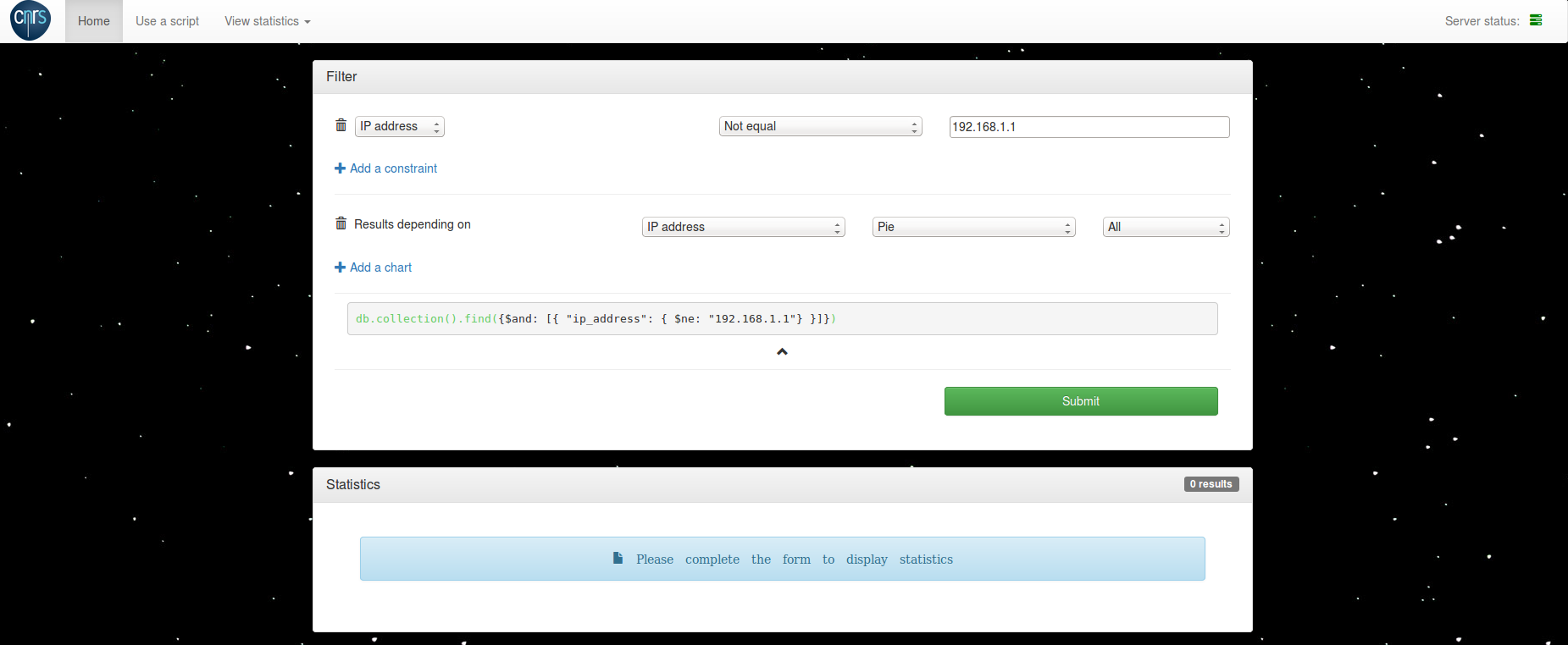
- Travail sur le site.
- Partie importation depuis MongoDB:
- Modification de la partie client. Les traitements des champs se font à présent du côté serveur.
- Champ "own query" ajouté et adapté.
- Ajout de quelques champs permettant de choisir les graphiques que l'on souhaite afficher.
- Ajout d'un champ "query" qui permet l'affichage de la requête finale.
- *28
- Travail sur la gestion de l'affichage des graphique suivant les choix de l'utilisateur. Réunion avec M. André Schaaff et Mme Anaïs Oberto afin que je sache ce que souhaite avoir comme résultat le directeur.
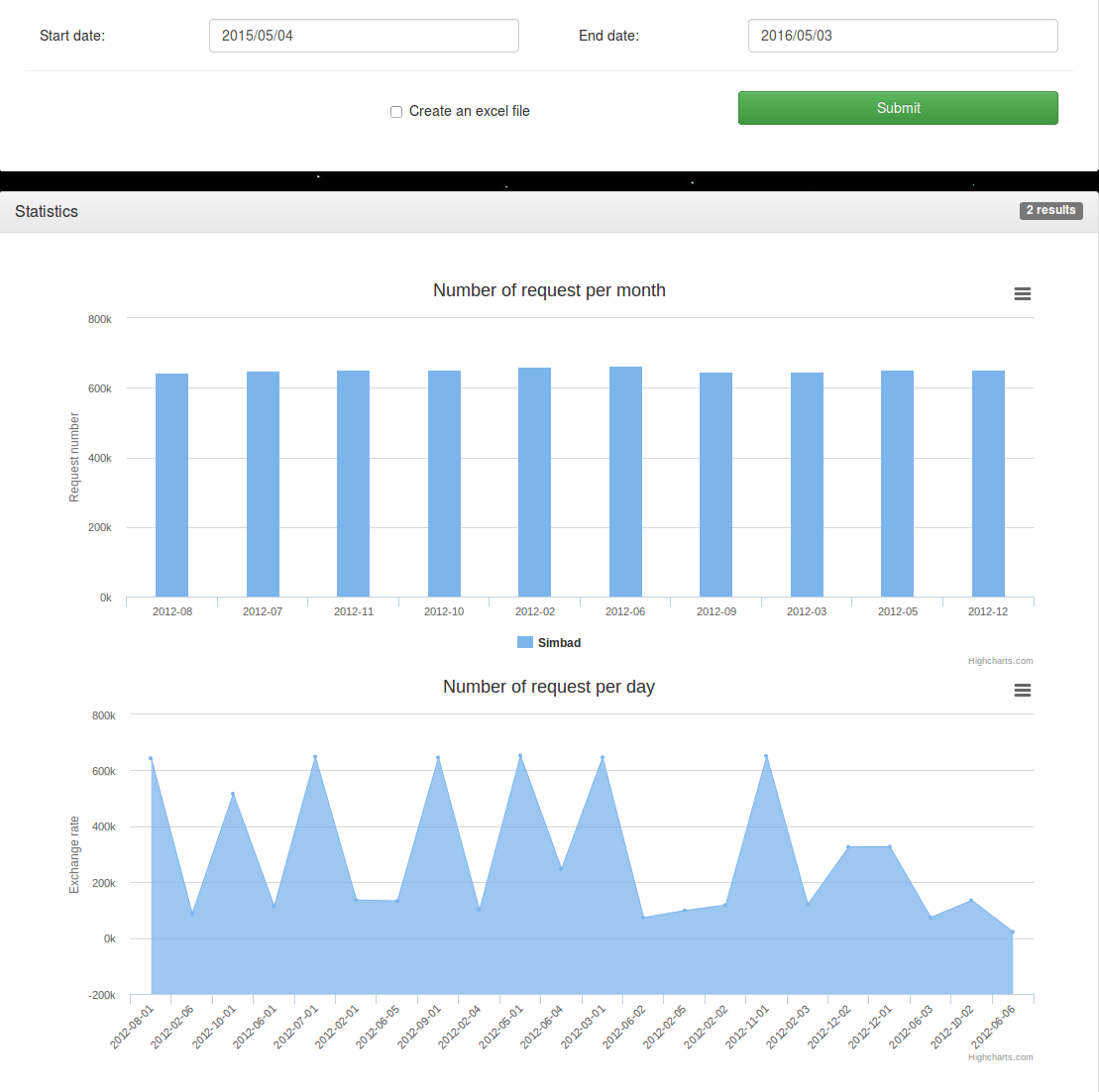
- Le bilan de cette réunion concerne la création d'une page simplifiée qui génère l'affichage de graphiques suivant une date de début et une date de fin.
- Graphique du nombre de requêtes concernant chaque service par année.
- Graphique du nombre de requêtes concernant chaque service par mois.
- Graphique du nombre de requêtes concernant chaque service par jour.
- *29
- Travail sur cette nouvelle mission. Réunion avec Mme Anaïs Oberto concernant l'exportation de la base de données de MongoDB pour la création d'une base de données de tests.
Mai
- *02
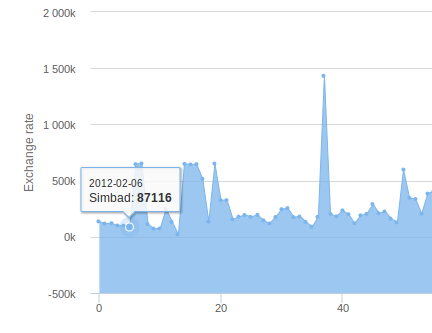
- L'application donne des résultats par jour et par mois pour le service simbad. Léger soucis, les données reçues par MongoDB ne sont pas triées dans l'ordre, ce qui provoque lors de la génération des graphiques un ordre illogique.

- *03
- Réunion avec le directeur du CDS, M. André Schaaff et Mme Anaïs Oberto. Bilan :
- Différentes machines renvoient des logs pour les services Simbad/ Aladin / Vizier qui seront traités et adaptés au format de la nouvelle base de données.
- Avec cette base de données le directeur souhaite
- Un affichage du nombre de requêtes par jour/mois/année pour les différents services.
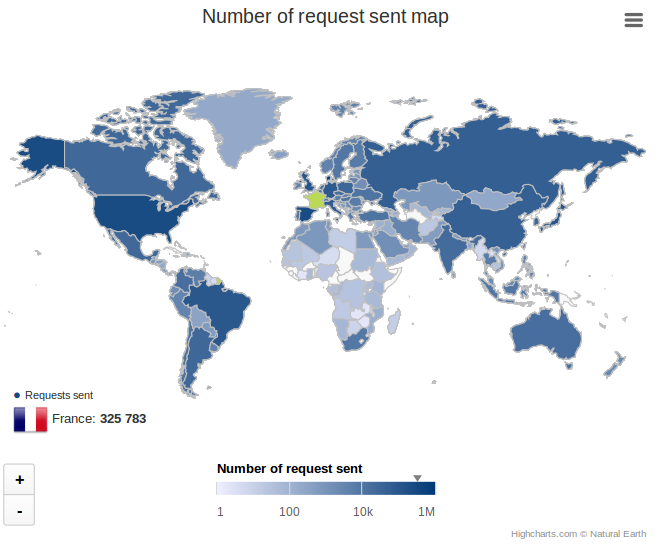
- Un affichage des lieux où ont été faites ces requêtes sur une année.
- Avec cette base de données le directeur souhaite
- Conception d'une requête mongoDB prenant le plus de données utiles possible.
- Réalisation d'un premier fichier excel utilisant les données reçues grâce au module "msexcel-builder".
- Changement du plan, l'affichage de la page web prennant trop de temps avec la vrai base de données je dois réaliser un script python permettant de regrouper par jour les données et de les insérer dans une nouvelle base de données.
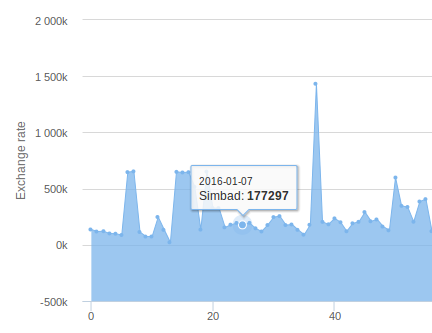
 Un problème apparaît. Je dois réussir à faire que l'axe x face apparaître la date de chaque jour.
Un problème apparaît. Je dois réussir à faire que l'axe x face apparaître la date de chaque jour.

 $ : Réunion avec Mme Anaïs Oberto. Bilan :
$ : Réunion avec Mme Anaïs Oberto. Bilan : - Il faut ajouter la possibiliter d'entrer des valeurs pour deux arguments ( date de début / de fin ) pour le script python permettant le traitement des données de la bdd logs vers la bdd logsnumber ( ne gardant qu'une date et le nombre de ligne existantes à cette date )
- Il faut voir s'il n'est pas possible grâce à highchart d'exporter les données directement en format xls.
- Il faut voir pour le traitement des adresses ip le format demandé par HighChart et les sites disponibles pour réaliser ce traitement.
- *10
- Ajout de la possibiliter d'entrer des valeurs ( date de début / de fin ) pour le script python permettant le traitement des données de la bdd logs vers la bdd logsnumber ( ne gardant qu'une date et le nombre de ligne existantes à cette date ) Ajout du plugin permettant d'exporter les données en format xls grâce à highchart. Travail sur le script python permettant de traiter les adresses ip.
- *11
- Le script python permettant de gérer les adresses ip fonctionne mais prend trop de temps à s'exécuter. ( 5 minutes pour une journée )
- *12
- Travail sur la réception, la mise en forme des données de mongodb sur node.js et l'ajout d'un graphique cartographique highchart
- *13
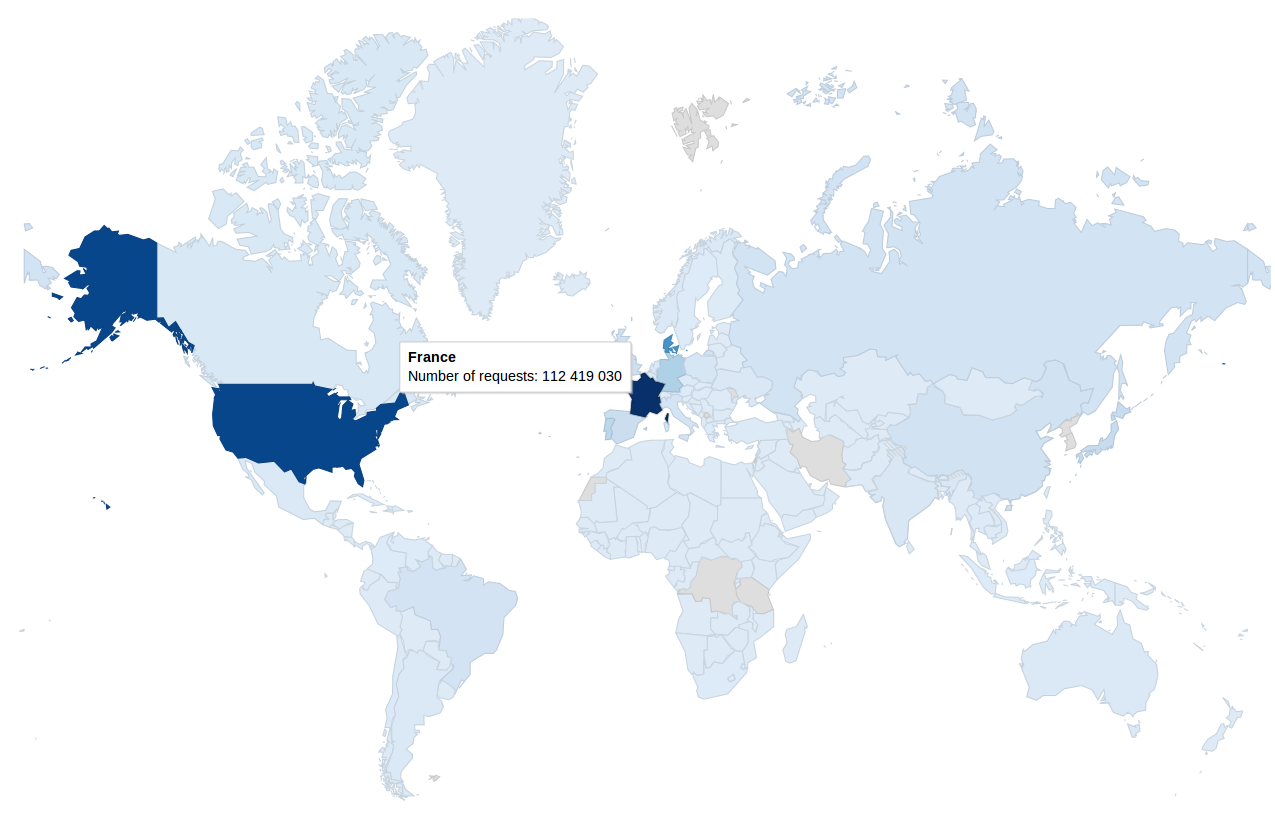
- Aujourd'hui j'ai pu travailler sur la réalisation du graphique de la carte. Durant une discution avec Mme Anaïs Oberto je me suis rendu compte que j'avais mal compris le résultat souhaité par le directeur. J'ai modifié mon code en conséquence. J'ai aussi eu un problème de compatibilité entre Highchart et Highmap. Finallement la carte s'affiche et grâce à elle, il est possible, en survolant une zone de voir le nom du pays ainsi que le nombre de requêtes envoyée depuis celui-ci.

- *17
- La carte du nombre de requêtes effectuées par lieux pour chaque service s'affichent correctement. La légende en bas de la carte est générée en fonction du nombre maximal de requêtes envoyées depuis un même lieu. Néanmoins un soucis s'est ajouté : lorsqu'on scroll et qu'on arrive à l'affichage des cartes, le navigateur met du temps à scroll.

- *18
- Correction de quelques erreurs et ajout des vrais valeurs pour mes deux nouvelles collections "logsnumber" et "logscountries" qui me permettent d'avoir des lignes de données allégées pour un affichage plus rapide. On peut voir s'afficher les graphiques liées aux données de la vrai base. Cependant une erreur apparaît rapidement :


- *19
- Highmaps fonctionne en utilisant des données sous cette forme : data = [{ code: "FR", flag: "fr", value: "315000"}] J'ai pu voir que ma requête MongoDB ne regroupait pas les données par code. Je pouvais donc avoir plusieur fois le code "FR" dans mon tableau data.
Après cette correction, toujours le même message d'erreur. J'ai donc vérifié qu'il n'y ai aucun conflit entre Highcharts et Highmaps en isolant Highmaps. Toujours la même erreur. J'ai donc regardé mes données et vérifié si ce n'était pas à cause du format d'un code en particulier que le script plantait. J'ai donc noté la majorité des codes disponibles sur Highmaps et j'ai supprimé toutes les lignes dont le code ne correspondait pas. Aucun changement, l'erreur persiste. - *20
- Réunion avec Mme Anaïs Oberto. On a pu discuter de choses à modifier sur le site . Elle m'a aussi donné des expliquations sur la rédaction de mon rapport de stage. A 15h comme prévu avec mon tuteur, Mme Anaïs Oberto et M. André Schaaff nous avons fait une réunion. Elle avait pour but que mon tuteur en sache plus sur le déroulement de mon stage et qu'il s'assure qu'il n'y ai aucun soucis. De plus on a pu mieux comprendre le déroulement de ma soutenance et parler de la rédaction de mon rapport.
- *23
- Ajout des arguments pour les scripts python et traque d'une erreur sur mon script de traitement des adresses IP.
- *24
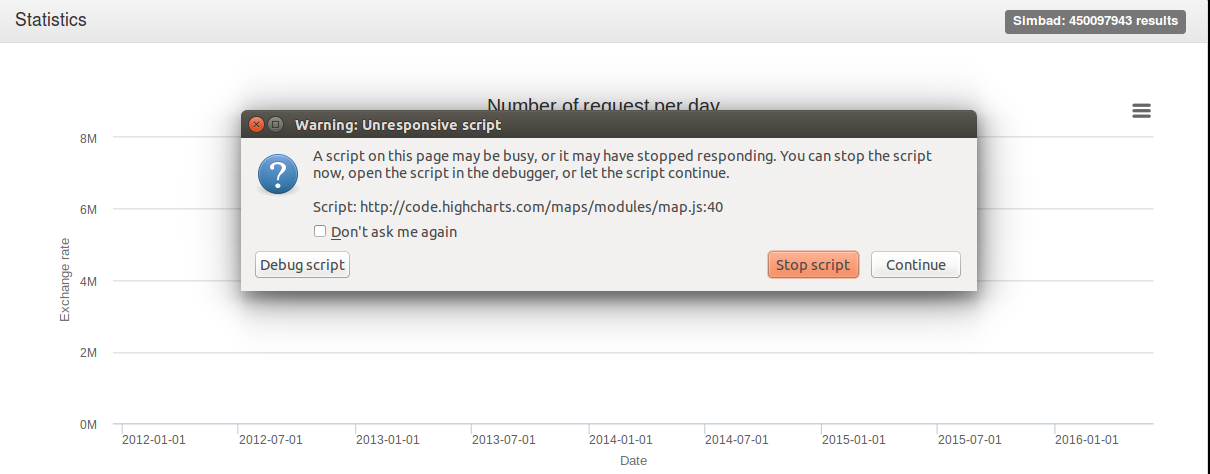
- Regroupement des scripts de chaque page et ajout des commentaires. Le script python a toujours une erreur différente. Travail sur la page "from_database", recherche d'une solution pour que celle-ci puisse se charger correctement et le plus rapidement possible.
- *25
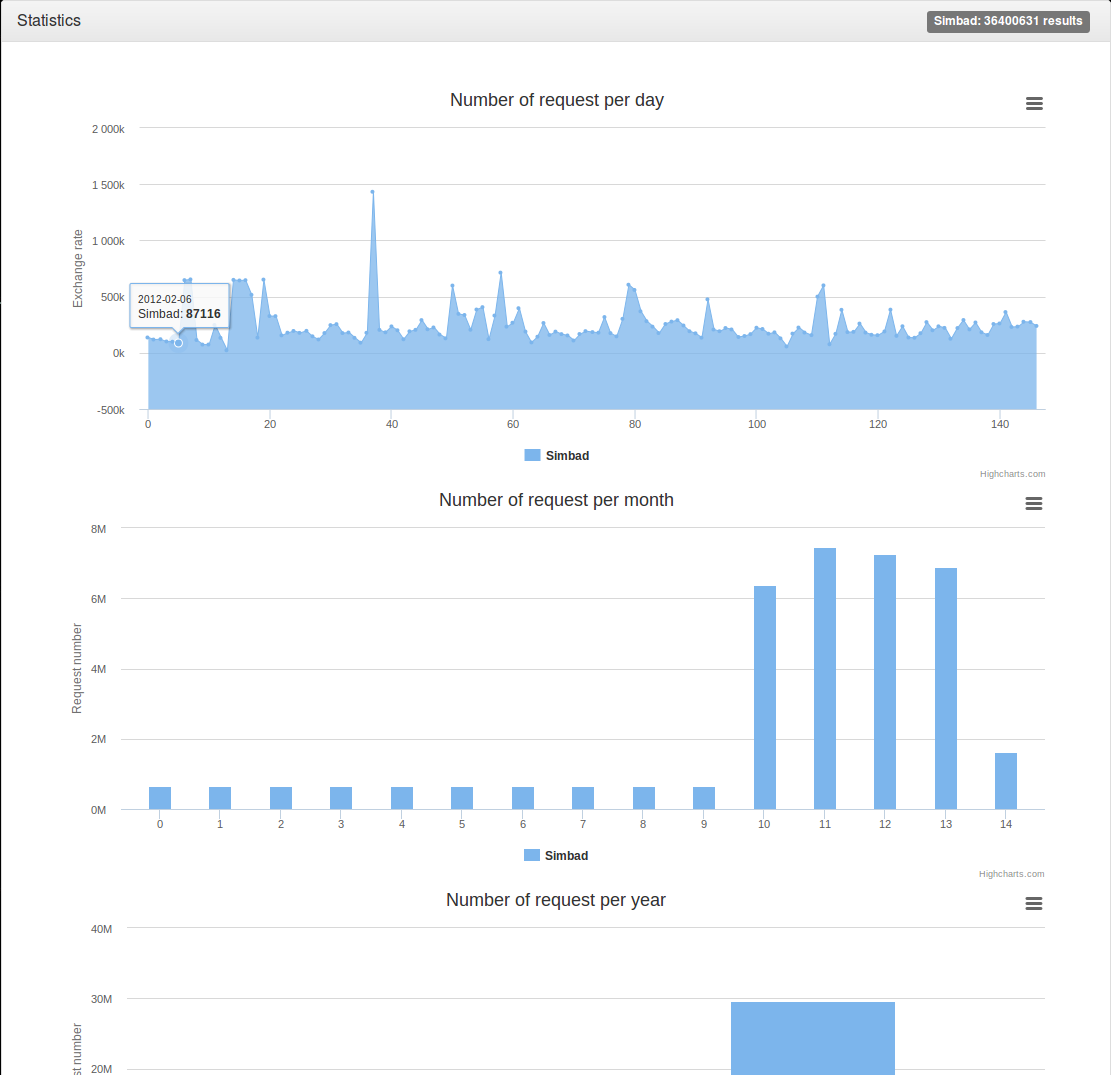
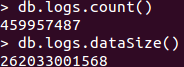
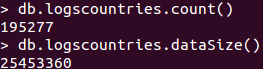
- Le script de traitement des adresses IP s'exécute à présent sans erreur et permet de réduire énormément le nombre de données. On a pour la base de données de base 459 957 487 lignes pour une taille de 244G
 Pour notre nouvelle collection réalisé grâce au script on a 195 277 lignes pour une taille de 0,02 G
Pour notre nouvelle collection réalisé grâce au script on a 195 277 lignes pour une taille de 0,02 G
 Modification du script pour la page "from_database" pour que l'affichage soit plus rapide et qu'il n'y ai plus besoin d'autant de mémoire.
Modification du script pour la page "from_database" pour que l'affichage soit plus rapide et qu'il n'y ai plus besoin d'autant de mémoire.Avant cette modification, le script abandonnait si on lui demandait un résultat sur un mois.

- *26
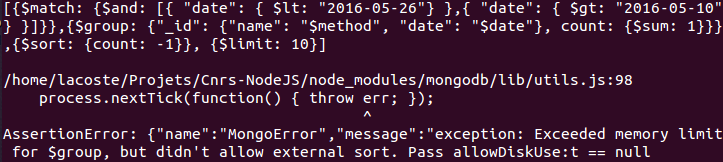
- Travail sur la page "from_database". Le message "out of memory" n'intervient plus lors de l'affichage des statistiques sous forme de graphique "pie" comme précisé sur le rapport de la journée du 25. Aujourd'hui j'ai rajouté l'affichage sous forme de graphique histogramme et à courbes et le message "out of memory" apparaît pour ces deux cas. J'ai pu faire des essais :

- *27
- Travail sur la page "from_database" et sur la remise en forme du code.
Ajout d'un moyen de sauvegarde de la configuration. Réunion avec Mme Anaïs Oberto. On a pu discuter du temps de réponse des requêtes et du problème avec la requête pour les histogrammes. - *30
- Demande d'utilisation de l'application par le directeur du CDS afin d'extraire des images statistiques.
Travail sur la page quick_stats. Les informations affichées pour les cartes contenaient des erreurs. Modifications du code quick_stats afin de le rendre plus lisible. - *31
- Travail sur les requêtes de la page "from_database". J'ai pu essayer la commande group(), celle-ci ne crash pas mais beaucoup de temps à renvoyer une réponse. $ : db.logs.group({key:{"date":1}, cond:{$and: [{ "date": { $lte: "2016-05-31"} }, { "date": { $gt: "2016-05-30"} }]}, reduce: function( curr, result ) {result.count++;}, initial: { count : 0 } })
- *01
- Réorganisation de code pour la mise à jour des collections. Séance planétarium. Travail sur l'étalage des couleurs de la carte Quick_Stats.
 -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
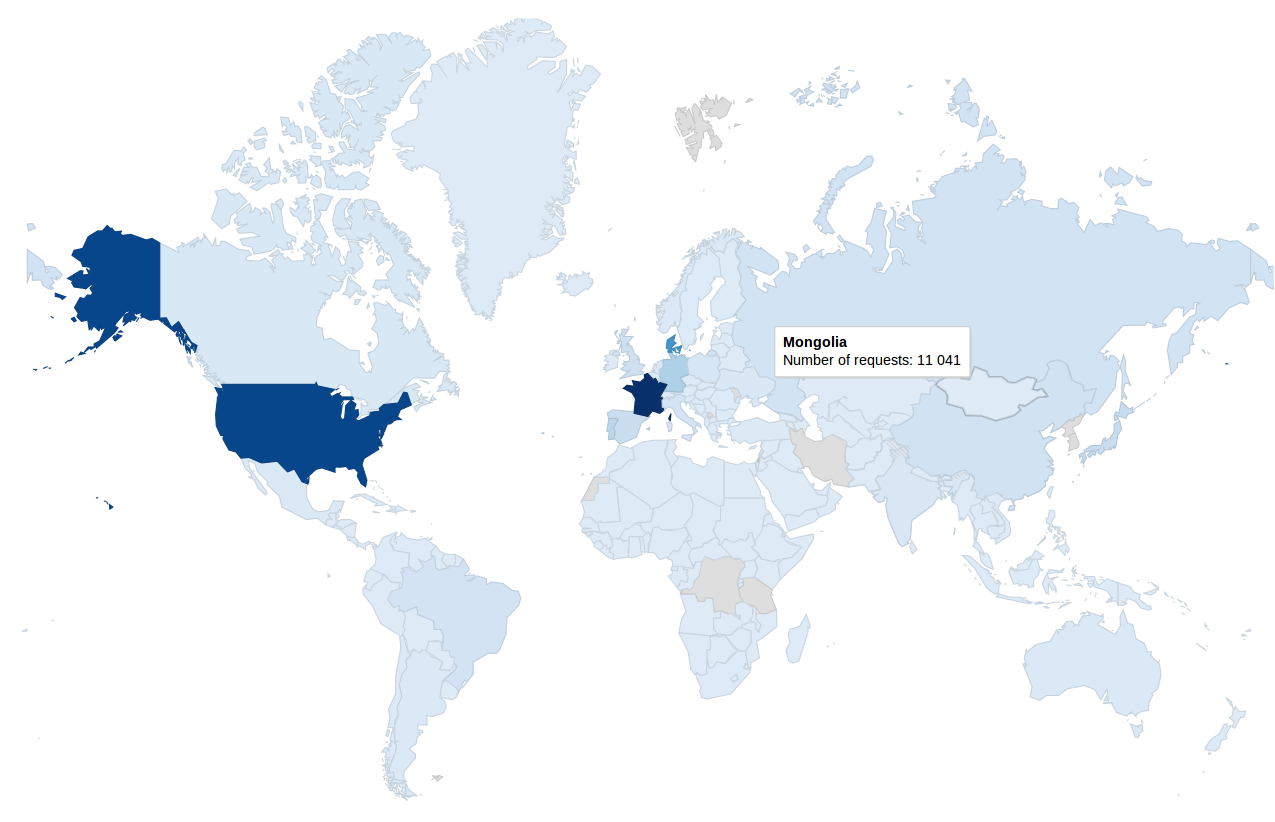
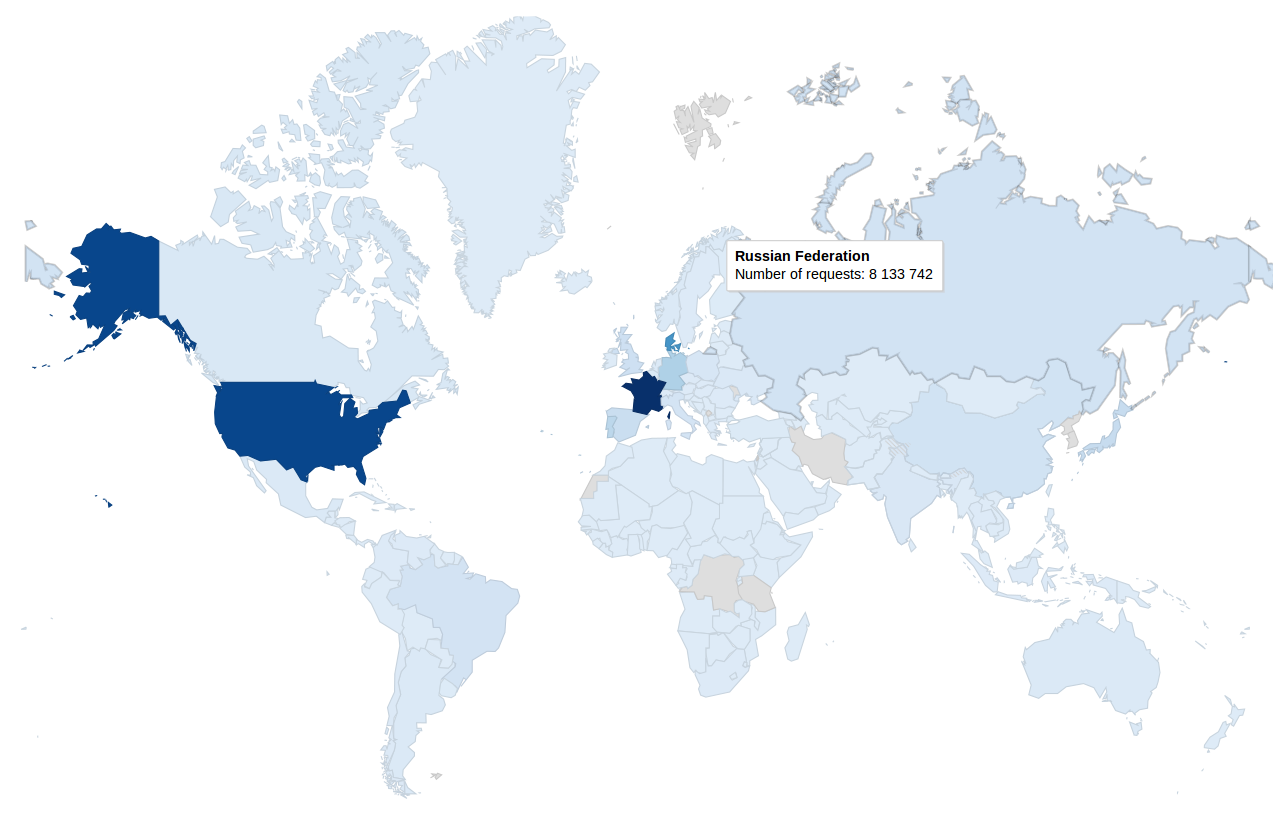
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------  En comparant la carte du dessus à celle du dessous nous pouvons voir que la valeur pour la Russie est 736 fois plus grande que la valeur pour la Mongolie et pourtant, la couleur ne permet pas de les différencier.
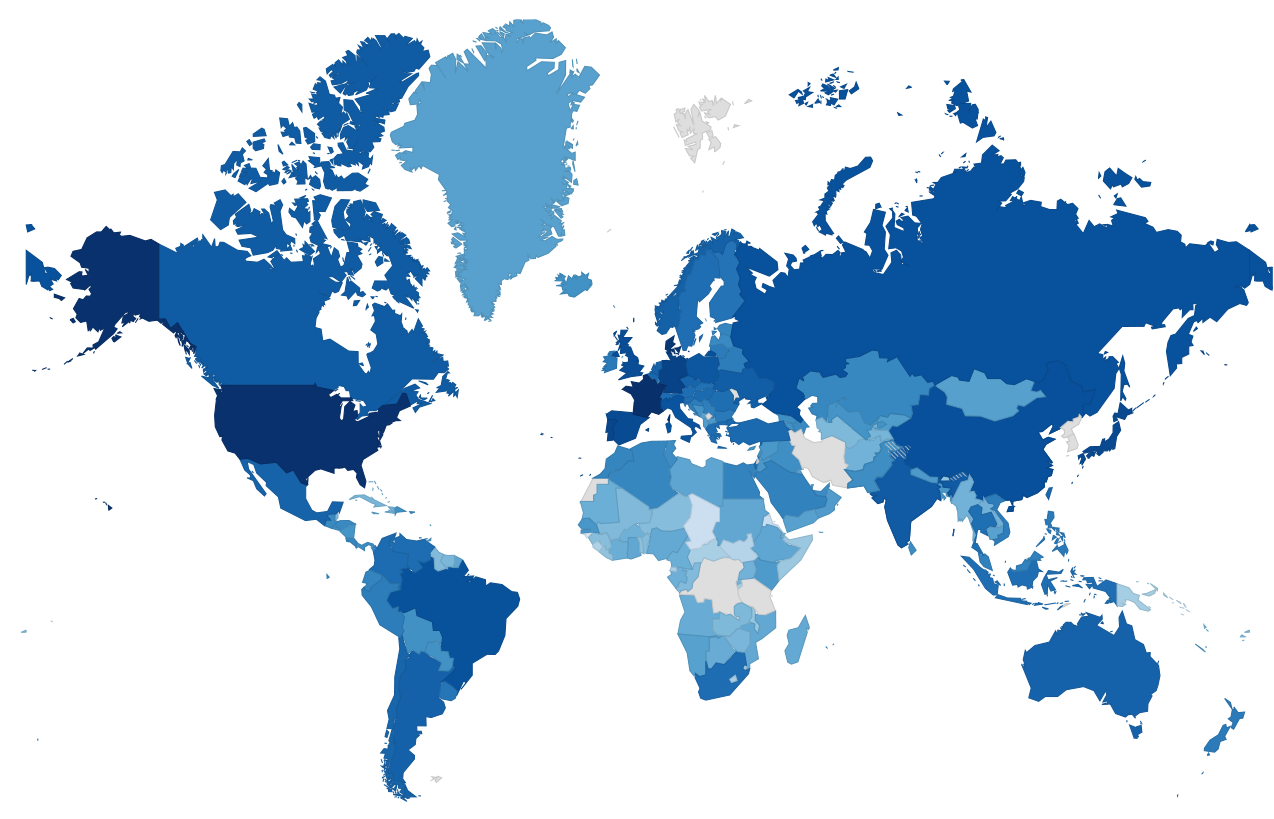
En comparant la carte du dessus à celle du dessous nous pouvons voir que la valeur pour la Russie est 736 fois plus grande que la valeur pour la Mongolie et pourtant, la couleur ne permet pas de les différencier.  J'ai donc utilisé le log de la valeur actuel pour faire l'étalage des couleurs. Voici le résultat:
J'ai donc utilisé le log de la valeur actuel pour faire l'étalage des couleurs. Voici le résultat:

- *02
- Les boutons de mise à jour pour la page Quick Stats sont fonctionnels. Modification de l'affichage de la page python et csv. Présoutenance.

- *03
- Modification du script python d'export des adresse IP. Comme demandé le script ne fait plus de requête pour avoir la liste des journées. Ajout des commentaires pour chacune des pages
- *06
- Travail sur la page script python. Modification de l'affichage, code et ajout des commentaires pour les scripts.
 Travail sur la page "from_csv", modification de l'affichage. Ajout de nouvelles routes.
Travail sur la page "from_csv", modification de l'affichage. Ajout de nouvelles routes. - *07
- Page Quick Stats ajout du nombre de requêtes total.
 Insertion d'alerte affichées sur la console et dans un fichier.
Insertion d'alerte affichées sur la console et dans un fichier.
 Correction du soucis d'affichage des erreurs de la page Quick Stat. Début de modification du code pour la construction des requêtes de la page "from_database".
Correction du soucis d'affichage des erreurs de la page Quick Stat. Début de modification du code pour la construction des requêtes de la page "from_database". - *08
- Correction des erreurs de mise à jour automatique des collections logsservice et logscountries. Si le serveur n'est pas interrompu, une mise à jour des collections "logsservice" et "logscountries" sera effectué tous les jours à 2:00 du matin.
- *09
- La mise à jour automatique fonctionne sans soucis :
 Correction d'une erreur qui pouvait afficher une erreur à la place de la carte des cartes de la page Quick_Stats
La page Quick_Stats affiche désormais les données des services avec des couleurs définis. Simbad, Aladin, Vizier. Il s'agit des couleurs affichées en bandeau sur les pages de http://cdsportal.u-strasbg.fr/
Correction d'une erreur qui pouvait afficher une erreur à la place de la carte des cartes de la page Quick_Stats
La page Quick_Stats affiche désormais les données des services avec des couleurs définis. Simbad, Aladin, Vizier. Il s'agit des couleurs affichées en bandeau sur les pages de http://cdsportal.u-strasbg.fr/ - *10
- Correction d'un soucis d'installation de GeoIP.
Juin
Sauvegardes
- à définir au cas par cas suivant le sujet du stage
Liens
- Logstash: logiciel permettant de générer des statistiques à partir des logs d’accès.
- Collecte, analyse, stockage: Logstash https://www.elastic.co/products/logstash
- Moteur de recherche utilisant une base de données NoSQL et RESTful: ElasticSearch https://www.elastic.co/fr/
- Recherche des infos stockées par Logstash dans ElasticSearch: Kibana https://www.elastic.co/products/kibana
- Highcharts:
- Permet de faire des schémas des statistiques: http://www.highcharts.com/
- Base de données utilisée pour recueillir les journaux d'accès: http://api.mongodb.org/python/current/tutorial.html?_ga=1.42108256.494348481.1428235462
- Python:
- Langage de programmation objet : https://openclassrooms.com/courses/apprenez-a-programmer-en-python
- Librairie permettant d'analyser l'utilisation des serveurs web en générant, à partir de leurs journaux d'accès sous forme de pages web: http://www.webalizer.org/
- Node.js:
- Permet de remplacer le serveur Apache et PHP en un serveur utilisant du Javascript : https://nodejs.org/en/docs/
- Utilise du Javascript Embedded (EJS)
- Mongoose est une librairie permettant de se connecter à MongoDB via Node.js: http://atinux.developpez.com/tutoriels/javascript/mongodb-nodejs-mongoose/
- MongoDB driver est un librairie qui tout comme Mongoose permet de se connecter à MongoDB. Il est plus simple à prendre en mains car il est moins structuré. http://mongodb.github.io/node-mongodb-native/
- L'utilisation de Socket.io permet au serveur de ne pas avoir à attendre une demande de l'utilisateur pour pouvoir lui envoyer une information (Communication en temps réel ): http://socket.io/


- Django
- Tout comme Node.js il permet de remplacer le PHP mais cette fois-ci par du Python : https://openclassrooms.com/courses/developpez-votre-site-web-avec-le-framework-django
- Utilise du Gabarit : https://docs.djangoproject.com/fr/1.9/ref/templates/language/
- Liste des filtres: https://docs.djangoproject.com/en/1.9/ref/templates/builtins/#built-in-filter-reference
- Liste des types de champs: https://docs.djangoproject.com/en/1.9/ref/models/fields/#field-types
- Liste des types de champs vérifiables: https://docs.djangoproject.com/en/1.9/ref/forms/fields/#built-in-field-classes
- Construction d'un formulaire : https://docs.djangoproject.com/fr/1.9/topics/forms/#rendering-form-error-messages
Versions testables
Testé sur ...
Documentation
Pour le moment tous les scripts de chaque page sont chargés lorsqu'une personne se connecte à une pageScript : L'utilisateur peut choisir suivant les scripts proposés. Les scripts proposés sont repris du fichier LIST.json du dossier python. Il contient des lignes au format json avec les caractéristiques suivantes :
- title : Titre du script affiché à l'écran de l'utilisateur.
- src : Source du script depuis le fichier serveur « app.js ».
- args : Arguments à envoyer au script. Il contient lui aussi plusieurs caractéristiques :
- title : Titre du champ de saisie affiché à l'écran
- type : Type du champ
- placeholder : Texte d'aide affiché à l'intérieur du champ
- required : « true » si le champ est obligatoire, sinon « false »
MongoDB : L'utilisateur peut choisir dans un premier select l'argument sur lequel il souhaite faire une requête. Les arguments sont les suivants :
- time : affiche comme 3ème champ un input
- ip address : affiche comme 3ème champ un input
- date : affiche comme 3ème champ un input
- user agent : affiche comme 3ème champ un select contenant les arguments suivants :
- mozilla ou windows
- service : affiche comme 3ème champ un select contenant les arguments suivants :
- simbad
- method : affiche comme 3ème champ un select contenant les arguments suivants :
- sim-script
- sim-tap/async
- sim-id
- sim-basic
- sim-nameresolver
- sim-normid
- sim-tap/sync
- sim-fid
- sim-red
- sim-fbasic
- own query : Affiche comme 3 ème champ un input permettant la saisie d'une requête complète.
- Equal to
- Not equal
- Greater than
- Lesser than
- Greater than or equal to
- Lesser than or equal to
- Contain
- Doesn't contain
- Camembert : Pour la « method »
Fichiers logs /csv : L'utilisateur peut, comme pour la partie script, choisir un fichier ou plusieurs fichiers suivant une liste proposée. Les scripts proposés sont repris du fichier LIST.json du dossier csv. Il contient des lignes au format json avec les caractéristiques suivantes :
- title : Titre du fichier affiché à l'écran de l'utilisateur.
- src : Source du script depuis le fichier serveur « app.js ».
- loadingBy : Nom de la fonction qui génèrera le graphique. Les noms disponibles sont :
- histogram_1
- area_1
- area_stat-simbad
Logstash/ElasticSearch/Kibana : Après avoir fait des essaies d'installation sur la machine « cds-stage-ms4 » le 18/04 j'ai pu voir qu'il y avait des conflits avec d'autres programmes. Le dimanche 24/04 j'ai donc créé une machine virtuel et réussi à installer ces programmes. Je dois donc à présent essayer de comprendre le fonctionnement de logstash/elasticSearch/kibana et les fonctionnalités disponibles.
- Rapport de stage:
- Présentation:
Installation
Installation de NodeJssudo apt-get install python-software-properties python g++ make
sudo add-apt-repository ppa:chris-lea/node.js
sudo apt-get update
sudo apt-get install nodejs
Si add-apt-repository ne fonctionne pas, télécharger software-properties-common avec la commande sudo apt-get install software-properties-common
cf: openclassroom
Les packages NPM
NodeJs permet l'utilisation de modules. Cela permet d'ajouter des fonctionnalités à notre serveur NodeJs.
Chacun des modules s'installe en local dans le dossier "node_modules" le plus proche, si nous avons plusieurs projet il faudra faire les installations pour chacun des dossier. Chaque module peut être installé grâce à la commande suivante : npm install nomdumodule
Il est donc possible d'appeler un module dans notre fichier serveur "/app.js" en ajoutant par exemple : var module = require('module');
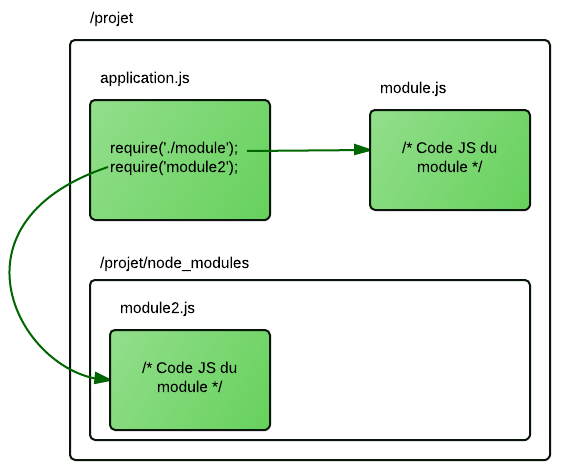 cf : openclassroom
cf : openclassroom
Si le projet est déjà créé, chacun des modules doit être noté dans le fichier "/package.json".
Dans notre cas nous avons: {
"name": "CdsLogs",
"version": "0.1.0",
"dependencies": {
"express": "~3.3.4",
"socket.io": "~1.2.1",
"ejs": "~2.4.1",
"mongodb": "~2.1.16",
"python-shell": "~0.4.0",
"node-schedule": "~1.1.0",
"bunyan": "~1.8.0",
"mv": "~2.1.1"
},
"author": {
"name": "Thierry Lacoste",
"email": "thierry.lacoste@etudiant.univ-reims.fr"
},
"description": "A web application to display statistics from access logs"
}
-
name : c'est le nom de votre application. Restez simple, évitez espaces et accents.
-
version : c'est le numéro de version de votre application. Il est composé d'un numéro de version majeure, de version mineure et de patch. cf: openclassroom
-
dependencies : c'est un tableau listant les noms des modules dont a besoin votre application pour fonctionner ainsi que les versions compatibles.
npm update pour installer et mettre à jour les modules.
cf: openclassroom
Les modules: - express: fournit des outils de base pour aller plus vite dans la création d'applications Node.js. cf: openclassroom ou npm
- socket.io: permet d'envoyer des informations au client sans devoir attendre une demande de sa part. cf: openclassroom ou npm
- ejs: permet de gérer les templates. cf: openclassroom ou npm
- mongodb: permet d'envoyer des requête à une base de données MongoDB. cf: npm
- python-shell: permet l'exécution de scripts python. cf: npm
- node-schedule: permet d'exécuter une action a une date, heure précise. Utilise du cron. cf: npm
- bunyan: permet de générer des logs et de les enregistrer. cf: npm
- mv: nécessaire à l'utilisation de bunyan. cf: npm
apt-get install libgeoip-dev
pip install GeoIP
If there is an error like : command 'gcc' failed with exit status 1
do :
sudo apt-get install python-dev
or for python3 use:
sudo apt-get install python3-dev
and redo pip install GeoIP
cf: github
Mise en place des collections
Pour notre projet nous utilisons deux collections nouvelles collections "logsservice" et "logsnumber" afin d'avoir des données pré-formatées.
Il est donc nécessaire de créer ces collections. Pour cela déplacez vous dans le dossier où se trouve les scripts :
cd media/python
Deux choix s'offrent à vous.
Les deux scripts vont extraire des informations de chaque ligne de la base de données, suivant la date de début jusqu'à aujourd'hui.
Sachant que la base de données contient des millions de lignes, cela peut prendre quelques heures.
Dans un premier cas vous pouvez donner la date la plus ancienne de votre base de données et vous aurez à patienter.
python IPtoCountryCode.py 2000-01-01
python exportToSmallerDB.py 2000-01-01
Dans un deuxième cas vous donnez un premier mois de votre base de données en précisant la date de fin. Cela vous permet de continuer votre travail, les collections seront mises à jour à 2:00 du matin et c'est donc à cette heure ci que les scripts prendront cette fois ci toutes les dates depuis la dernière date extraite (donc ici depuis 2000-02-01). Attention, si vous avez mis une date de début et une date de fin mais qu'à cette période il n'y a pas de lignes, cela provoquera un crash du serveur à 2:00.
python IPtoCountryCode.py 2000-01-01 2000-02-01
python exportToSmallerDB.py 2000-01-01 2000-02-01
Les modifications à faire:
- "/media/python" pour les scripts que vous souhaitez, modifiez les adresses et noms des bases de données et collections.
-"/app.js" faites de même pour les variables "urllogs" et "urllogscleared"
-"/views" regardez tous les fichiers de ce dossiers et des dossiers enfants et chercher "io.connect". Modifiez le chemin suivant le nom de votre machine.
Attention : Lorsque vous importerez le projet d'une machine à une autre, vérifiez que les fichiers ne soient pas verrouillés. Cela pourrait entrainer des erreurs.
Informations/travaux divers
- ...
Travail post stage éventuel
Liste des améliorations à envisager
Bugs connus
- *


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
ApplicationNodeJS-13042016.png | manage | 58.9 K | 2016-04-21 - 09:32 | UnknownUser | Screen of this statistics application |
| |
ApplicationNodeJS-21042016.png | manage | 96.3 K | 2016-04-21 - 09:32 | UnknownUser | Screen of this statistics application |
| |
Capture_du_2016-04-27_185954.png | manage | 77.8 K | 2016-04-27 - 17:00 | UnknownUser | |
| |
Capture_du_2016-05-03_095754.png | manage | 68.4 K | 2016-05-03 - 07:58 | UnknownUser | |
| |
Capture_du_2016-05-09_122130.png | manage | 67.2 K | 2016-05-09 - 10:22 | UnknownUser | |
| |
Capture_du_2016-05-09_1223.png | manage | 19.1 K | 2016-05-09 - 10:25 | UnknownUser | |
| |
Capture_du_2016-05-09_1224.png | manage | 18.9 K | 2016-05-09 - 10:25 | UnknownUser | |
| |
Capture_du_2016-05-13_1714.png | manage | 103.3 K | 2016-05-13 - 15:22 | UnknownUser | requests map |
| |
Capture_du_2016-05-17_1444.png | manage | 163.9 K | 2016-05-17 - 12:53 | UnknownUser | Cartes du nombre de requêtes envoyées pour chaque service |
| |
Capture_du_2016-05-18_1523.png | manage | 58.9 K | 2016-05-18 - 13:29 | UnknownUser | |
| |
Capture_du_2016-05-18_1535.png | manage | 61.7 K | 2016-05-18 - 13:37 | UnknownUser | |
| |
Capture_du_2016-05-25_1121.png | manage | 6.8 K | 2016-05-25 - 09:30 | UnknownUser | Database size |
| |
Capture_du_2016-05-25_1122.png | manage | 9.0 K | 2016-05-25 - 09:31 | UnknownUser | New collection size |
| |
Capture_du_2016-05-25_1409.png | manage | 12.3 K | 2016-05-25 - 15:42 | UnknownUser | Process out of memory. Abandon |
| |
Capture_du_2016-05-26_1636.png | manage | 33.1 K | 2016-05-26 - 14:37 | UnknownUser | Exceeded memory limit |
| |
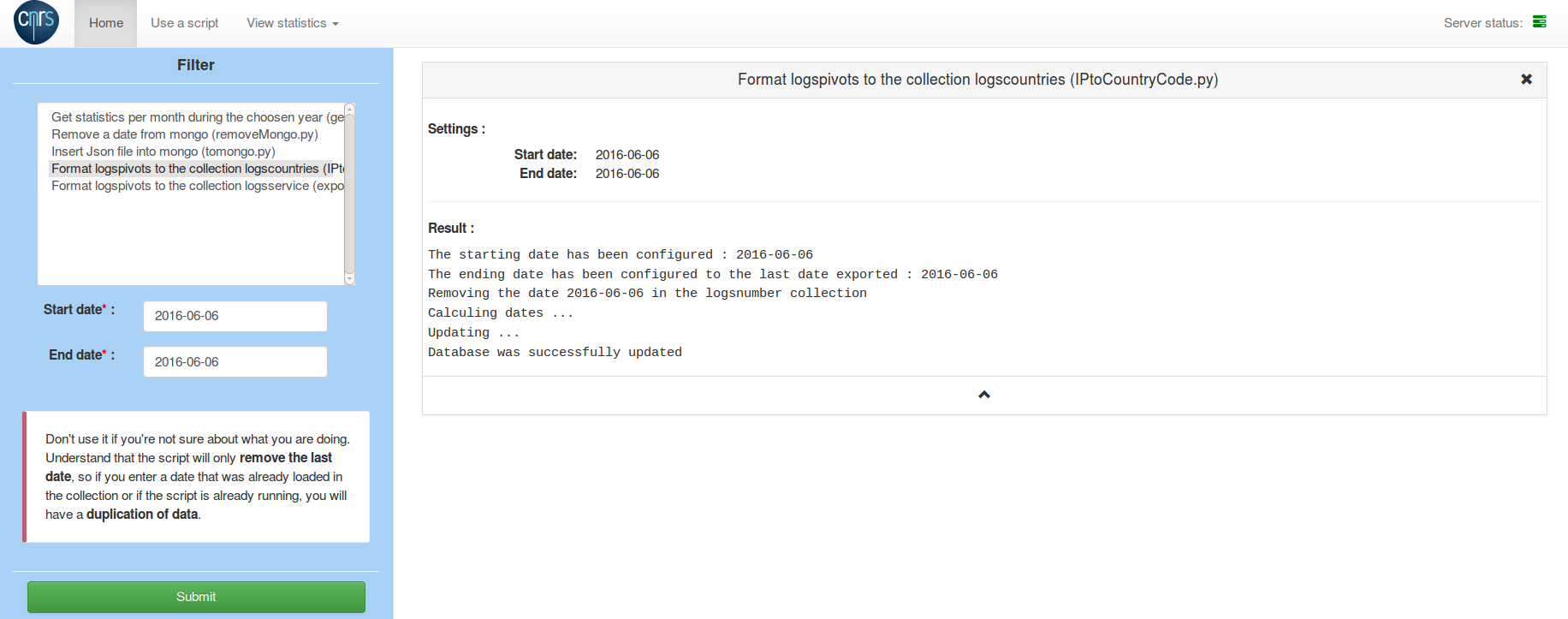
Capture_du_2016-05-31_1705.png | manage | 2.3 K | 2016-05-31 - 15:06 | UnknownUser | Query time |
| |
autoUpdate.png | manage | 64.6 K | 2016-06-09 - 07:29 | UnknownUser | The automatic updating is working well. |
| |
console.png | manage | 110.9 K | 2016-06-07 - 10:37 | UnknownUser | Logs |
| |
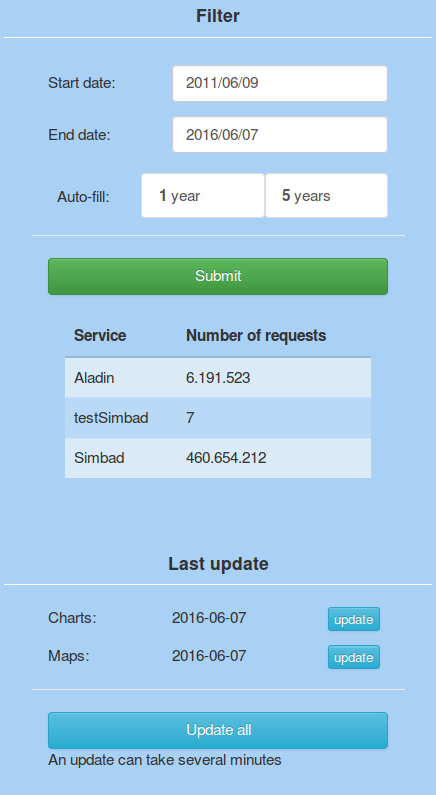
filter.png | manage | 28.2 K | 2016-06-06 - 13:01 | UnknownUser | |
| |
kibana-status.png | manage | 61.9 K | 2016-04-26 - 14:11 | UnknownUser | |
| |
kibana.png | manage | 158.7 K | 2016-04-26 - 14:00 | UnknownUser | |
| |
map0.png | manage | 243.1 K | 2016-06-06 - 12:41 | UnknownUser | Map widespread |
| |
map1.png | manage | 245.3 K | 2016-06-06 - 12:41 | UnknownUser | Map widespread |
| |
map2.png | manage | 254.4 K | 2016-06-06 - 12:41 | UnknownUser | Map widespread |
| |
map3.png | manage | 269.8 K | 2016-06-06 - 12:41 | UnknownUser | Map widespread |
| |
python.png | manage | 103.1 K | 2016-06-06 - 13:16 | UnknownUser | |
| |
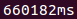
query.png | manage | 1.7 K | 2016-06-08 - 13:16 | UnknownUser | Time for query : db.logs.aggregate([{$match: {$and: [{date: {"$lte": "2016-06-08" }}, {date: {">": "2015-06-09" }}]}},{$group: {"_id": {"name": "$service"}, count: {$sum: 1}}},{$sort: {count: -1}}, {$limit: 5}]) |
| |
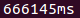
query2.png | manage | 1.3 K | 2016-06-08 - 13:19 | UnknownUser | Time for query : db.logs.aggregate([{$match: {$and: [{date: {"$lte": "2016-06-08" , ">": "2015-06-09" }}]}},{$group: {"_id": {"name": "$service"}, count: {$sum: 1}}},{$sort: {count: -1}}, {$limit: 5}]) |
| |
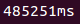
query3.png | manage | 1.6 K | 2016-06-08 - 16:32 | UnknownUser | Time for query with an histogram |
| |
result.png | manage | 39.5 K | 2016-06-07 - 10:32 | UnknownUser | Number of requests |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
|
Ideas, requests, problems regarding TWiki? Send feedback