Utilizing Dynamic Form Generation and Image map Techniques to Construct
an Interface to an Astronomical and Geophysical INGRES Database
B.N. Dorland, W.A. Snyder
E.O. Hulburt Center for Space Research
U.S. Naval Research Laboratory
R.D. Jones, S. Heinicke
Hughes STX Corporation
D.A. Becker
Massachusetts Institute of Technology Media Laboratory
Table of Contents
- Abstract
- Introduction and Background Information on
Metadata Catalog Databases
- Accessing the Metadata Catalogs With Dynamic
HTML Forms
- Enhancement of the Interface by means of
Dynamic Image Maps
- Summary
- Contacting the Authors
- Appendix A: A Technical Discussion of the Dynamic
Forms INGRES Interface
1. Abstract
The Backgrounds Data Center (BDC)
, located in the Space Sciences Division
(SSD) of the
Naval Research Laboratory (NRL),
is the designated archive for celestial and earth backgrounds data collected
by Ballistic Missile Defense Organization
(BMDO)
science research programs, including the upcoming Midcourse Space Experiment
(MSX) data set.
We extract and populate relational database catalogs with
metadata and these catalogs to locate
archived data products which our users request. The advent of Jason Ng's
(NCSA) GSQL protocols have allowed us to construct World Wide Web interfaces
to our catalogs, greatly improving their utility to users. We have modified
these scripts to work with our INGRES RDBMS.
We have enhanced the standard GSQL interface by incorporating
the use of "on the fly" form and
graphical image construction. With
dynamic forms, users generate their own forms by pre-selecting those query
parameters they wish to use to search on databases. Users can also select
query complexity ranging from rank novice to direct interaction with Standard
Query Language (SQL). Dynamic image mapping adds a graphical layer to the
WWW forms
interface, and permits users to select data by interacting with images only.
These techniques allow for an uncluttered and intuitive representation of the
catalog databases to users.
2. Introduction and Background Information on
Metadata Catalog Databases
2.1 Introduction
The BDC is responsible for the archiving of science data
from a multitude of United States Department of Defense (DoD) research
programs. Currently, data holdings are near one terabyte in size. We
expect that within a few years the BDC will be the archive for tens of
terabytes of data. These data include celestial backgrounds, atmospheric
and geophysical observations and cover the spectrum from the extreme
ultraviolet to the far-infrared.
Most of the expected new data will be from the Midcourse Space Experiment
(MSX)
which is scheduled for launch this year. MSX is a multi-sensor spacecraft
which will obtain spectral, radiometric and image data of the Earth and the
celestial backgrounds in the UV, Visible and IR regions of the spectrum. The
MSX Program has expended great effort to ensure that the archived data will
be readily accessible to users.
We have found that a primary challenge in being an archive center is in
locating specific data items which satisfies a user's needs. To this end, we
catalog all of
the data products which enter our archive center in one or more (depending
on the program) catalog databases. Our catalog system utilizes the INGRES
Relational Database Management System (RDBMS) and Standard Query Language
(SQL). The challenge we have faced is to allow our users to access these
databases in an easy and useful way.
2.2 Purpose
The purpose of this paper will be to provide some background on our use of
metadata catalogs for tracking our archived data products, then discuss in
depth our implementation of a WWW-based interface to our catalogs. We will
note some of the problems users encounter with traditional, vt100-style
interfaces to RDBMS catalogs, and will discuss our solutions to these
problems. An appendix
has also been included to provide a more technical report on our dynamic
forms interface.
2.3 A Brief Discussion of Metadata Catalogs
We locate archived data at our data center by keeping track of all the
products
we receive in a system of metadata catalogs. By
metadata we mean
information which describes the actual data product. For
example, the IR spectra of the central region of the Small Magellanic Cloud
is
data, but information about when the data was taken, what filter was used in
the instrument, the RA and DEC of the instrument's line-of-sight, etc., is
what we call metadata.
Population of the database is accomplished by extracting the relevant
metadata directly from the incoming data in an automated fashion. This
metadata is then entered into detailed, program-specific catalogs or into
a less detailed, comprehensive summary catalog.
The summary catalog entries relate datasets (e.g. an orbital pass, a single
observation event composed of multiple exposures, etc.) and associated
metadata ranges.
The method for locating datasets using the summary catalog is to construct a
range query for some set of metadata parameters and submit it to the catalog
database. This query (or question) results either in a
negative answer, or a list of datasets which satisfies the query. The
investigator can order the dataset(s) and then use the much more detailed
information in the associated program (detailed) catalog to select and locate
actual data items such as scenes (images) or spectra.
The user interacts with the catalog databases by means of the interface or
interfaces which have been set up. The critical task of the interface is
to mediate between the user and the database. The interface must allow the
user to develop questions and submit these questions to the databases without
knowing the query language. The development of an interface that is
both powerful and easy to use to the non-SQL versed user is very difficult.
With the advent of the WWW and WWW protocols to interface with SQL databases,
this task has become much easier.
3.1 The Problem: Database Interface Trade-Offs
The interface permits users to connect to the catalog, construct and submit
queries, and receive and properly interpret results. The actual
implementation of the interface has always been
a problem, however.
In building an interface, one is typically forced to make a number of
choices.
These choices take the form of 'trade-offs', and as the name suggests,
choosing
one option over another is not easy. Each option has both pro and con
associated with it. Should the interface be easy to use or should it allow
for many options and be somewhat complex in presentation? One could argue
both
sides of this question, and depending on the target audience of users, one
option may be preferable to the other for a specific implementation. We have
found that the trade-offs which present the most problems are:
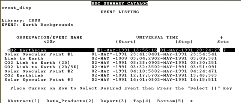
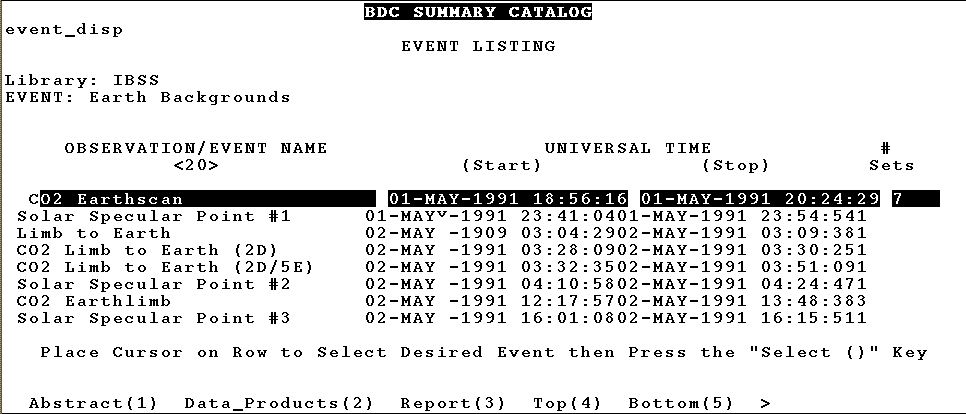
Fig. 1: Older, vt100-style catalog interface
- Standardization vs. Power
- This trade-off can take the form of having to choose between a very
powerful
graphical interface or a much more limited but standard
interface, such as VT100-style emulation (see fig.1)
. The problem is that the powerful
interfaces are typically restricted to certain platforms (e.g. an HP
workstation) or even certain windowing environments (e.g. GL) and simply will
not run on other machines. Standardization is not yet universal across
platforms,
so software which allows for emulation must run at a "least common
denominator" level. The more powerful interface might be perfectly suited to
a situation where there is standardization among query-interface machines,
such as when there is only one workstation used for the interface, or when a
company enforces a standardized interface environment. Our user base is
dispersed and heterogeneous. In the past we have built both types of
interfaces; first, simple VT100 emulations for general use and specialized
graphical interfaces for use at our analysis facility.
- Ease of Use vs. Versatility
- The interface to a database should be easy to use. This truism is often
hard
to implement, however. One way to construct a very easy to use interface is
to make it simple and uncluttered. Present the user with a few choices and
make their format intuitive to the user. Unfortunately, by
making the choices few and by making them simple, the versatility of the
interface suffers. Users cannot specify precisely what they want because the
interface may not permit formulation of the query in a manner consistent
with the user's desires.
One solution to the simplicity problem is to present the user with many
possible choices. The user still employs the interface to handle to database
transactions, but now has a large number of choices from which to choose.
Unfortunately, the more information which is presented to the user, the more
complex the interface becomes. Our program catalog for MSX, for example, has
hundreds of settings to select specific instruments, filters, observation
sets, lighting conditions , etc. Wading through all of these selections can
be tedious and hierarchical interface layers can confuse the user before a
complete query can be constructed.
Another solution is to remove the interface altogether and permit direct
access using SQL. Users must be SQL experts and must have access to database
dictionaries, etc. for this to work. This is asking a lot of the typical
investigator who is interested in getting the data, not in learning database
query language.
We have attacked this problem by building what we call a dynamic forms SQL
interface. This initial interface was based on Jason Ng's (NCSA) GSQL
program. We have built an interface to our summary catalog using HTML forms
to
translate user inputs into SQL queries. These queries are then used by the
HTTPD
server residing on an SGI
4D35 workstation to query an INGRES RDBMS residing on a VAX 4300.
The technical details regarding the our actual implementation are available
in Appendix A.
The HTML form appeared to us to be the perfect
tool for connecting users to a catalog database. It is standard across all
supported hardware configurations, and it is inherently easy to use and has
the potential (implementation is a different matter) for being intuitive in
use. We initially constructed a form which contained all possible query
parameters
and provided that to the user. What we found, however, was that even at the
high level of granularity
of our summary catalog, and dealing solely with a limited number of query
parameters, our form was cumbersome to use. Any thought of using this method
for preparing queries for highly detailed program catalogs was unacceptable.
Furthermore, a rigid form interface does not address the issue of ease of use
vs. versatility. We still had to make compromises between giving the user a
lot of choices and not making the task an impossible one to manage by non-SQL
experts.
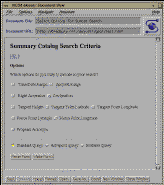
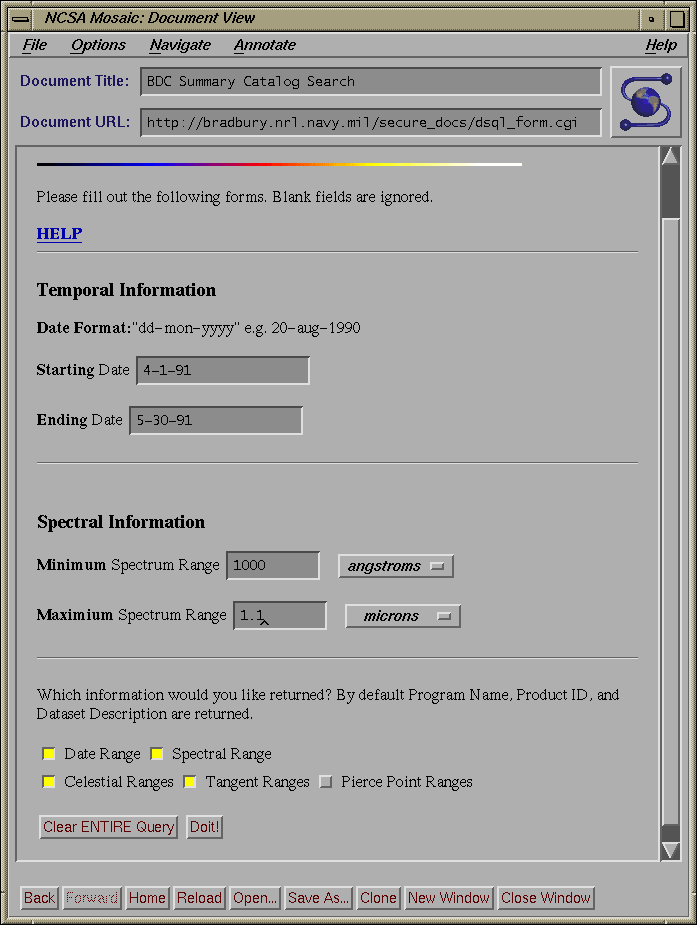
Fig. 2: Parameter Selection Form
We determined the best way of addressing these issues was to make our form
interface dynamic. A preliminary page (see fig.2)
which contains a list of all query parameters that can be used to search our
catalogs mediates between the user and the
query form. Users initially select whatever query parameters they want to
use, hit the "build form" button and a form is built with just the requested
elements.
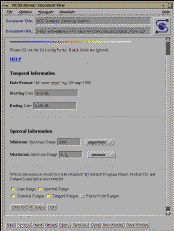
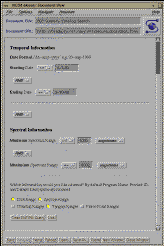
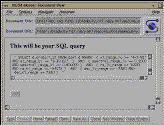
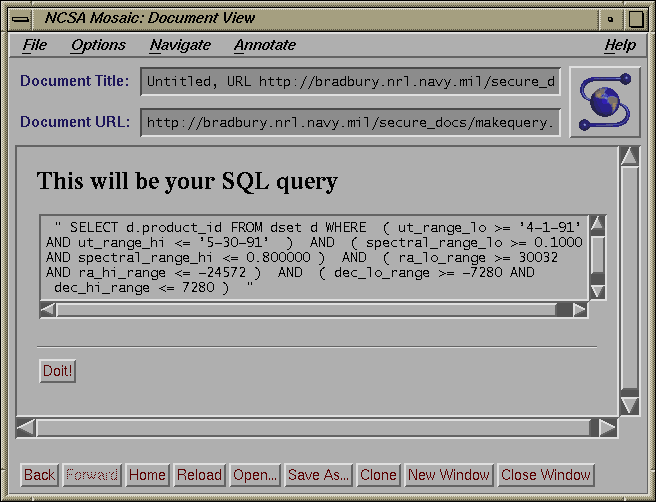
Fig. 3a, b, c: Standard and Advanced Query Forms and the Editable Query
box
These forms include sample query parameters.
Furthermore, they choose the type of query built from a list of
three possibilities: standard, expert, or editable SQL
(see fig. 3 a, b, c ).
A standard query is one where users merely have to indicate high and low
ranges and the interface builds the query with all possible cases. The
advanced query gives users control over how the range specifications will be
used to construct queries (e.g. >=parameter a, < parameter b), and the
Boolean relation between
the parameters. The editable form is similar to the advanced interface, but
instead of processing the query, the SQL query is built and then displayed
to the
user who may then edit the query language before it is submitted to the
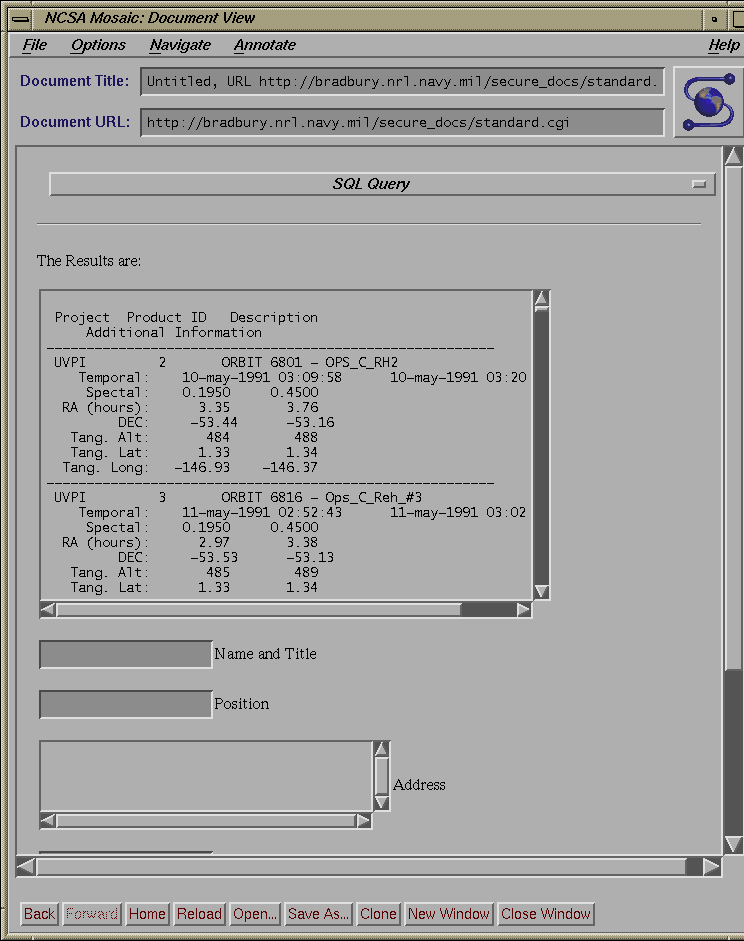
catalog. The results of the query are returned to the
user as a scroll-box text message which he can then submit as an order to
our order processing system (see fig. 4). In
addition to permitting the construction of the customized input form,
output fields can be specified so that the user may request only that
metadata
range results which are needed.
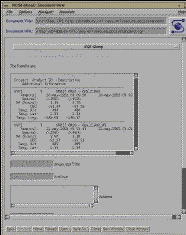
Fig. 4: Result of Query to Summary Catalog
This form can be submitted to the Archive Center's
Order Processing system
3.3 Implications of the dynamic form of querying Metadata catalogs
With this method in place, building queries for metadata catalogs can now be
done at the level of complexity and required expertise of the user's
choosing. Furthermore:
- All queries, no matter how complex the final form of the query
language, can be constructed easily with no knowledge of databases.
- Databases with a large number of possible input parameters can now be
presented to the user without any complexity beyond what is needed.
- Interface
with the database can now occur at the level of expertise the user chooses.
This includes:
- The investigator with no knowledge of SQL or catalogs uses the
interfaces which does all the sorting of Boolean and range relationships for
him
- The investigator who wants some specific control over the final form
of the query can be provided with a more advanced interface to the SQL
query construction
- The investigator who is the expert SQL user can now create and modify
raw SQL through another interface.
Thus, the problems noted above, viz. standardization vs. power and
ease-of-use vs. versatility are both satisfactorily addressed.
The system of dynamic forms provides users of scientific databases with a
user-friendly, powerful, and flexible tool for interrogating the
databases.
The next step to make the database interface more intuitive is move beyond
the forms-based interface and develop an graphical one. We are now
investigating adding such a graphical layer between the user and the
forms interface that would permit even easier construction of queries.
The goal of such an effort would be to make interaction with the database
so easy and intuitive that the user would not be aware that database
operations
were being performed. Users would be able to simply point and click
on a map or other graphical tool and obtain the requested information and
data.
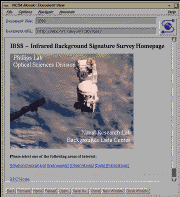
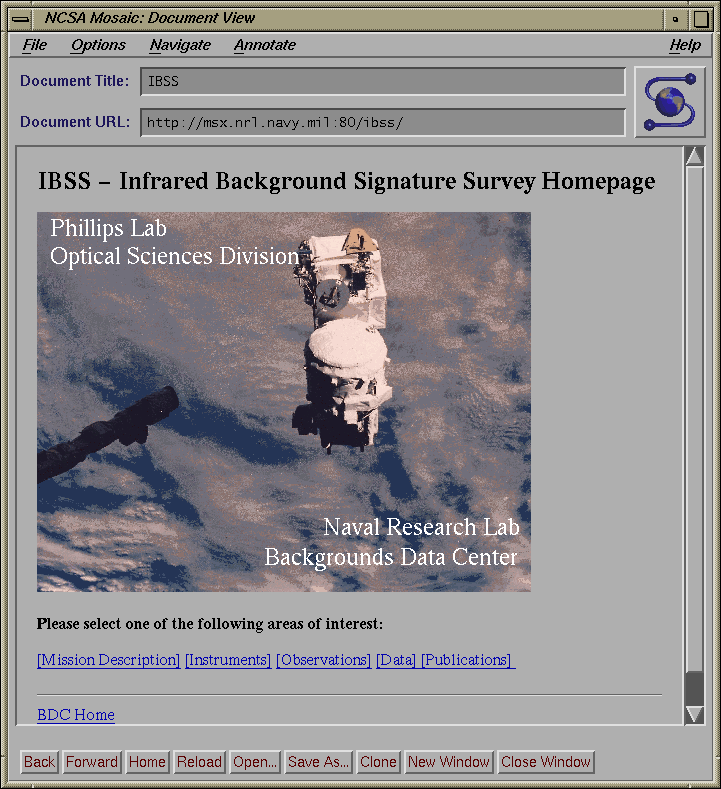
Fig. 5: IBSS Homepage
We have built a prototype version of this system for the Infrared Background
Signature Survey (IBSS), a DoD experiment program that included Earth
backgrounds observations using radiometer, spectrometer and imager data taken
predominantly in the IR (see fig. 5). We have
successfully petitioned the DoD to publicly
release all of the Earth backgrounds data. We have placed all of the IBSS
data on-line and constructed a World Wide Web system for accessing this data
using dynamic image map construction.
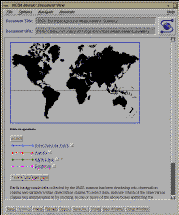
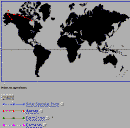
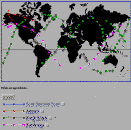
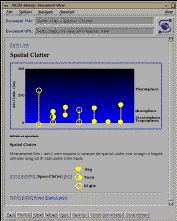
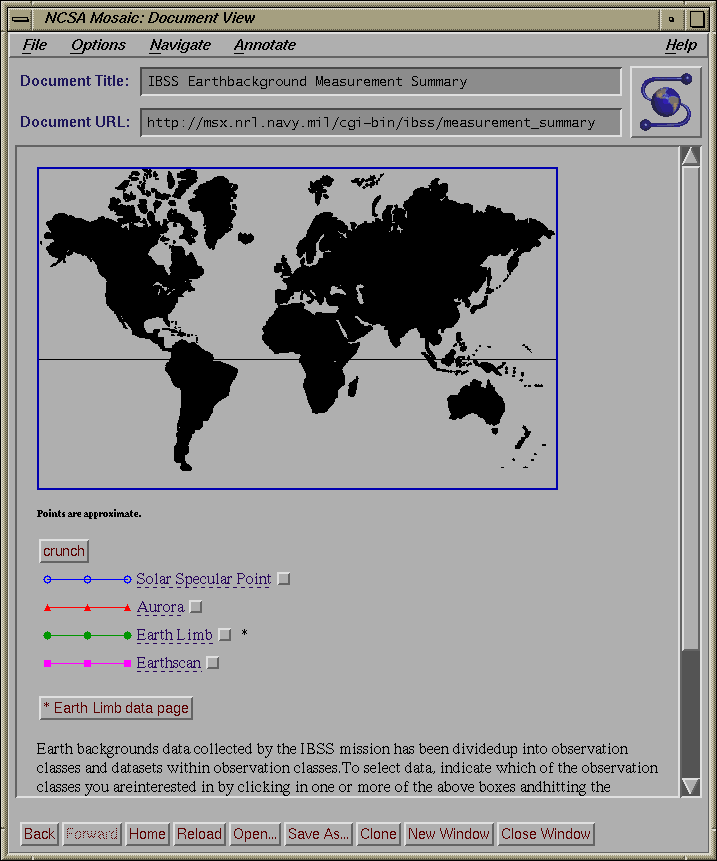
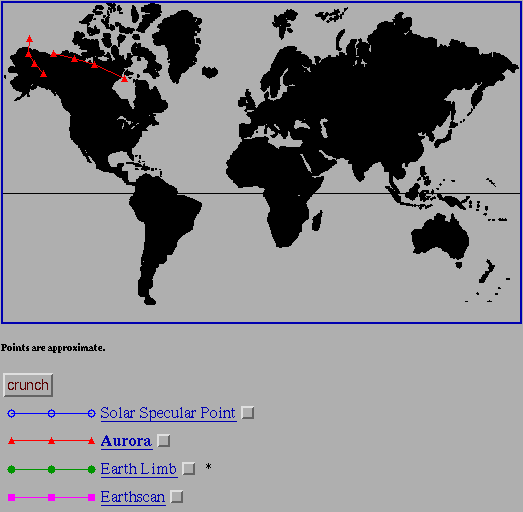
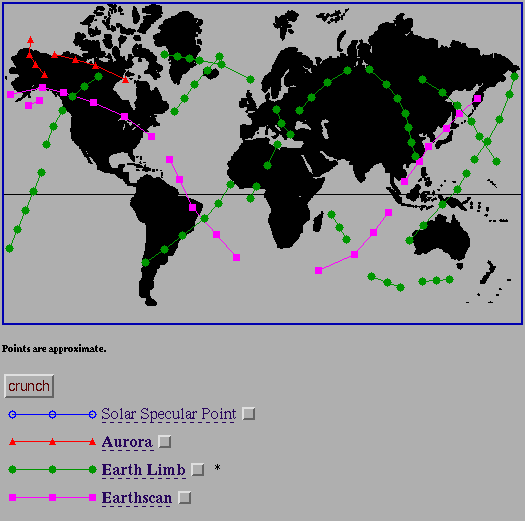
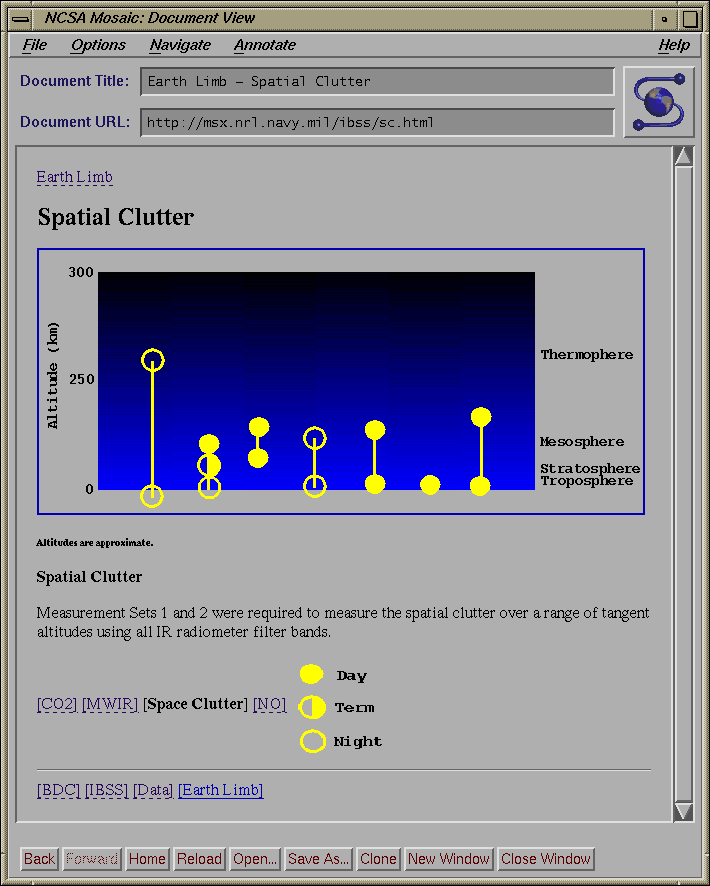
Fig. 6a, b, c, d: Dynamic Image Map Data Selection Tools for IBSS
Shown: a) Initial interface b) Auroral Observations selected c) Multiple
observations selected d) Earth limb atmospheric cross-section
The initial IBSS screen (see fig. 6a) displays a
map of the Earth and a list
of the observation types that are available. These include various earth
scan,
solar specular point, auroral, and earth limb observations. The data is
presented at the same level as in the summary catalog, viz. in the
dataset
group. For example, a single auroral observation over Alaska with a twelve
minute duration is a single data set (see fig. 6b)
. To determine what data
is available, the user can select one or more observation types, hit the
return button, and an on-the-fly .gif image map is created which displays
only the traces of the selected observations. An example is shown in
fig. 6c where the user has selected all of the
Earth-looking/Earth limb
observations. Earth limb observations are presented as plots on a image of
the cross-section of the atmosphere
(see fig. 6d), supplemented by tangent
line-of-sight sub-point traces on the face of the earth. To avoid the
clutter problem (similar to the clutter forms mentioned earlier), a user can
select only those observation types of interested, and a dynamic map is built
which displays only the traces of interest. A user points and clicks on or
near a dataset of interest in order to receive the science data
(see fig. 7).
A typical session might occur like this: An investigator interested in
Earth backgrounds auroral data obtained over Alaska is alerted to the
presence of potentially useful IBSS data.
This might occur, for example, through the use of NASA's Master Directory.
The
investigator connects to the IBSS homepage and examines the instrument
and observation descriptions to determine if the data set is of real
interest. If
the answer is yes, he would move on to the data selection section. The
investigator
selects the "Aurora" button and hits "crunch". A map is
returned which displays
the two IBSS data sets of auroral data taken over Alaska and northern Canada
(fig. 6b, above).
The
investigator is interested in the westernmost of the two datasets and points
and
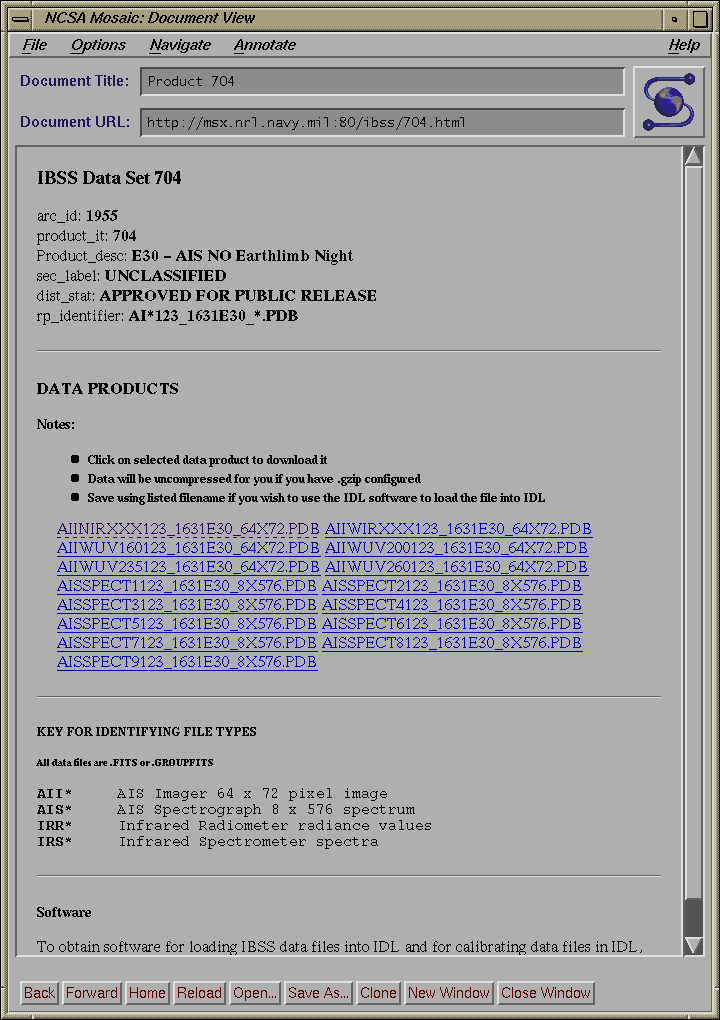
clicks on this one. A dataset page is returned to him with a brief
description of
the data, a "download" link for the science data, and a link to the software
page
which contains IBSS calibration software. He downloads his data and logs off
the homepage system.
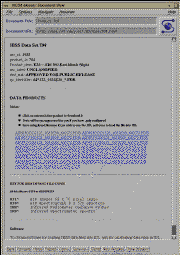
Fig. 7: Data Products page returned to user after use of selection
tool
The use of graphics must be done prudently, however, as not all information
is
displayed best in that form. Spectral ranges, for example, do not gain
anything by being displayed as a rainbow; in fact they may lose some
precision
if actual numbers are not entered into a field. Graphics
should part of the entire
interface and not an outright replacement. The importance of the graphical
interface is the appearance of simplicity. Users merely point and click in
a completely intuitive manner. Within a few "clicks", they have
obtained the
data or information of interest.
In this paper we have described how we have used on-the-fly dynamic form and
dynamic map creation to address common database interface problems of
standardization verses power and ease of use verses versatility. With
dynamic
forms, users effectively generate their own interface containing only those
metadata parameters needed to specify their database query and also specify
the level at which they choose to interact with the relational database.
Dynamic image mapping adds a graphical layer to the WWW forms interface, and
permits users to select data by interacting with images only. These
techniques
allow an uncluttered and intuitive representation of metadata catalog
databases to our users and enhances their ability to find and request data of
interest.
Please contact the authors at the following Internet email addresses. URLs
for hompages are provided, if appropriate.
The Summary Catalog Interface consists of several programs, written in
C, that utilize the Common Gateway Interface (CGI). The interface is
based on Jason Ng's (NCSA) GSQL program.
When a user first enters the summary catalog interface he will see a
form that consists of 10 CHECKBOX buttons, 3 RADIO buttons, and 2
buttons for resetting and submitting (please see figure
2
in body of paper). Each of the CHECKBOX buttons
corresponds to a query element (i.e. time/date range, spectral range,
etc..) and each of the RADIO buttons corresponds to a type of query
form (i.e. standard, advanced, or editable). Once the user has
selected the desired query elements and the type of query the
contents of the form are submitted using the POST method to
dsql_form.cgi.
Next, Dsql_form.cgi takes the input (passed through STDIN, as per POST
method) from the initial form and builds a form that contains only
those elements selected on the initial form. The form generated by
dsql_form.cgi comes in two flavors. If the standard option is
selected, the form only has INPUT fields for the minimum and maximum
of each query element. If either the advanced or editable query type
are selected, a form is generated that contains not only INPUT fields
for the minimum and maximum of each query element, but also SELECT
fields that contain logical operators (AND, OR) for combining the
various parts of the queries and range operators ( >=,>,=,<>,<,<= )
which affect the range of the queries. Both flavors will have a MULTIPLE
SELECT field if the Program Acronym element was selected. In addition
at the bottom of each form, are five CHECKBOX buttons that allow the
user to choose what type of information he wants returned from the
query. The user can select information regarding: temporal
ranges, spectral ranges, celestial ranges (i.e. RA and DEC), tangent
point ranges and pierce point ranges. The contents of this form are
submitted with the POST method to one of three shell scripts depending
on the type of query. The shell scripts are necessary to set certain
PATH information for use by INGRES.
Once the PATH information is set, the scripts call their respective
programs which parse the data, build an SQL query and submit it to
INGRES for processing. Each of the three programs are slightly
different.
The Standard Program takes the inputs and builds a
standard query. This standard query is an expert level SQL query
which performs two actions for the user. First, the query returns a maximum
number of data sets which meet the given parameters. This is achieved
by building the query so that the data set's minimum value for a given
parameter (e.g. the data set's minimum RA) has to be less than the
maximum value for the parameter provided by the user and the data
set's maximum value for a given parameter (e.g. the data set's maximum
RA) has to be greater than the minimum value for the parameter
provided by the user. This ensures the database returns all data sets
which have values in the ranges provided by the user. Second, the
query takes into account the circular nature of several of the
parameters ( RA, longitude). These parameters are particularly
complicated to work with for two reasons:
- the maximum value entered by the user can be less than the
minimum value entered by the user, and
- the maximum data set value for an entry can be less than the
minimum value for the entry.
The Advanced Program and the Editable Program take the inputs and
build the query as defined by the user (remember that with the
advanced and editable queries, the user selects both logical and range
operators). Once the queries are built they are passed to a back-end
written in C and embedded SQL. Before the Editable Program
submits the query to INGRES, it first displays the query in a
user-editable TEXT field. If the user wishes, he can modify the query
before submitting it to the back-end. The back-end submits the query to
the INGRES database, which processes it and returns both the standard
results (Program Acronym, Product ID, and Dataset Description), and
any additional information (Temporal Ranges, Spectral Ranges,
Celestial Ranges, Tangent Point Ranges, and Pierce Point Ranges) the
user requested.